

Par Guillaume Caballé - TheExpert Squad, Ingénieur Virtualisation
OpenStack, Projet Open Source
Bien que jeune arrivant dans le paysage technologique informatique, OpenStack a pourtant acquis rapidement une popularité notable dans le déploiement de clouds privés. Ce premier article a pour vocation de présenter la solution dans son ensemble ; un second sera ensuite dédié aux choix d’architectures possibles et au rôle de l’architecte en général.
Initialement, le projet naît du besoin de deux acteurs : la NASA, et l’hébergeur RackSpace. En Juin 2010, l’agence décidait de connecter ses serveurs virtuels Nova au système de stockage de données Swift hébergés par le provider. Fort de leurs succès, ils publient la première version du projet OpenStack, nommé Austin, en Octobre 2010.
Chaque année, le lieu où se déroule l’OpenStack Design Summit détermine le nom de la future version. Celles-ci suivent également un ordre alphabétique. Ainsi, la première release d’OpenStack se nomme Austin, la seconde Bexar, la troisième Cactus, etc… Pour plus d’informations sur ces releases : https://releases.openstack.org/

Il est important de savoir qu’OpenStack est un projet de développement : le site openstack.org ne fournit aucune référence ou distribution. Cependant, des vendeurs externes (Mirantis, Ubuntu, SUSE, …) peuvent créer leur propre distribution basé sur le code Python du projet.
OpenStack Foundation & ses contributeurs
Le projet OpenStack est régit par une fondation. L’adhésion à celle-ci est gratuite et ouverte à tous : elle compte aujourd’hui plus d’une dizaine de milliers de membres.
Un Comité Technique de 13 personnes, élu par les membres, assure la direction et l’encadrement des questions techniques. De la même manière, un Conseil d’Administration traite les questions d’ordre financier et stratégique. Celui-ci inclue des personnes nommées par les entreprises sponsors et d’autres également élues par les membres.
Pour plus d’information sur la fondation : https://www.openstack.org/foundation/
Le projet bénéficie de nombreuses contributions, que ce soit de contributeurs Open Source classiques :
- RedHat
- IBM
- HP
Mais aussi d’entreprises entièrement dédiées à OpenStack :
- Mirantis
- CloudBase
Ces contributions peuvent avoir plusieurs formes :
- Nouvelles fonctionnalités
- Drivers pour des services spécifiques (drivers pour stockage bloc Cinder ou drivers Software Defined Network (SDN) pour Neutron)
- Corrections de bugs
Un nuage de services
Suite à la première version, qui n’incluait que les services Nova et Swift, beaucoup d’autres sont venus étoffer le projet:
- Glance (stockage d’image) est apparu sur la version Bexar
- Keystone (identification) et Horizon (web console) sont apparus sur la version Essex
- Quantum (service réseau), renommé par la suite Neutron, ainsi que Cinder(stockage bloc) sont apparus dans la version Folsom
- Heat (service d’orchestration) et Ceilometer (télémétrie) sont apparus dans la version Havana
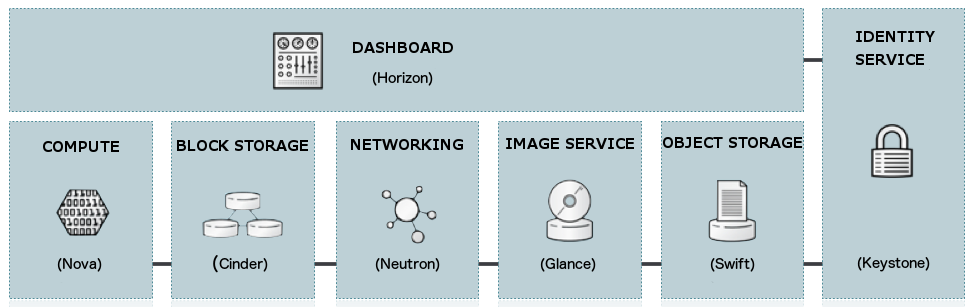
L’intégration de services continue d’être au centre du projet OpenStack, dans le but d’ajouter de nouvelles fonctionnalités. Elles sont introduites au fur et à mesure dans un cycle de développement et de sortie d’environ 6 mois.
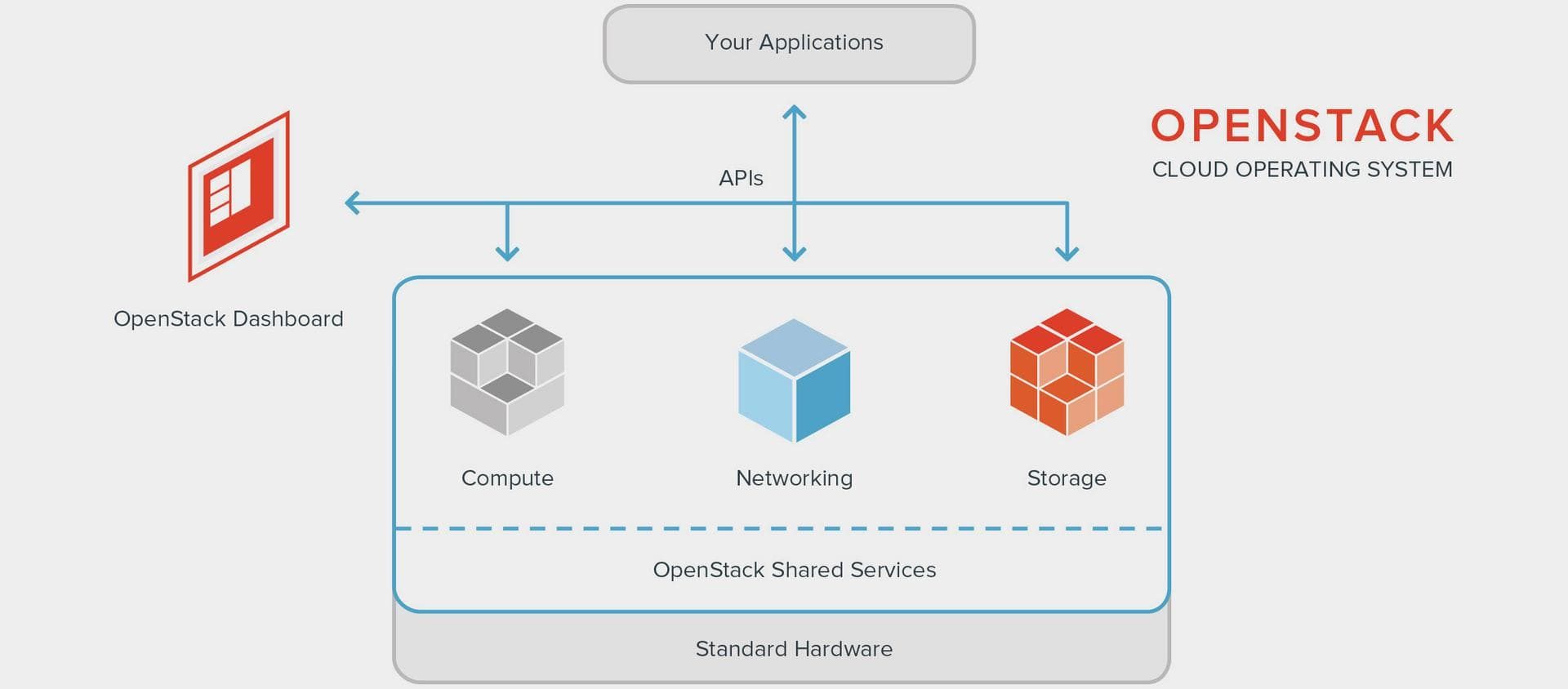
Chacune des fonctionnalités intégrées à OpenStack expose une REST API. Afin d’y accéder, des commandes console sont disponibles (commandes du client commun openstack) ainsi qu’une interface Web (Horizon), mais la plupart des interactions entre les composants et les utilisateurs se réalisent via les APIs, et ce pour plusieurs raisons :
- le système déployé peut être entièrement automatisé
- l’intégration avec d’autres systèmes (solutions d’orchestration) est clairement définie
- les cas d’utilisation sont facilement mis en œuvre et automatiquement testés.
C’est bien beau tout ça, mais…
Vous devriez maintenant avoir une meilleure idée de ce qu’est le projet OpenStack. Néanmoins, un point crucial manque à cette présentation : mais à quoi ce projet sert-il ?
Il est difficile d’avoir une réponse claire et précise à cette question. En réalité, OpenStack se définit plus facilement par ses cas d’utilisation (Use Cases). En effet, les utilisateurs approchent cette solution avec des objectifs différents à l’esprit. Ceux-ci peuvent être, parmi d’autres :
- Déployer une infrastructure de services partagée entre plusieurs clients. Ce Use Case est particulièrement présent chez les hébergeurs, comme RackSpace. On parle de plateforme multitenant.
- Mettre en place un mécanisme de Continuous Integration and Continuous Delivery (CI/CD) dans le cadre de développement rapide d’applications. C’est le Use Case le plus rencontré en entreprise. (92% des utilisateurs OpenStack ont des workflows CI/CD
sur leurs clouds privés pour la release Kilo) - Fournir une infrastructure permettant de déployer des fonctions réseaux automatiquement de façon logicielle. C’est le Use Case nommé Software-Defined Networking (SDN), le plus fréquemment rencontré chez les opérateurs télécoms actuellement.
- Gérer une infrastructure ayant un très grand besoin de ressources de calcul : on parle alors de High Performance Computing (HPC). On rencontre ce Use Case notamment dans le domaine de la recherche (CERN, NASA, MIT, DAIR).
Pour plus de détails sur le Use Case SDN, je vous invite à lire l’article SQUAD à ce sujet : https://theexpert.squad.fr/theexpert/cloud/apres-le-cloud-place-aux-reseaux-programmables/
L’enjeu de l’architecture
On voit à travers cette liste non exhaustive qu’OpenStack fournit un ensemble de services hétérogènes. Ensuite, l’entreprise doit décider si cette technologie répond à son besoin, et si l’implémentation de celle-ci s’intègre dans son contexte.
Dans un premier temps, elle peut choisir de déployer une architecture « référence », où tous les services seront présents et actifs. Mais il est conseillé d’implémenter en production exclusivement les services utilisés. Cela permet de limiter par la suite la configuration et les tests nécessaires à l’implémentation.
Les déploiements « référence » font souvent office de PoC (Proof of Concept), lorsqu’un Use Case n’est pas encore assez mature pour définir l’état final de la production.
C’est ici que l’architecture concernant OpenStack entre en jeu. Tout d’abord, Il s’agira de lister les besoins de l’entreprise et proposer une solution d’infrastructure satisfaisante. Ensuite, il sera nécessaire de maintenir des documentations de design et de déploiement cohérentes.
En conséquence, l’architecte devra posséder des connaissances approfondies de la solution, couplées à des compétences en architecture réseau et stockage. Ces différentes étapes seront abordées dans un prochain article.
Ressources
- OpenStack for Architects – Michael Solberg, Ben Silverman (2017)
- Certified OpenStack Administrator Study Guide – Andrey Markelov (2016)
- OpenStack Administration with Ansible 2 – Walter Bentley (2016)

