![[Rappel] Protection des données - les méthodes existantes](/media/cache/01/a0/01a0c2aab7e47d905990376e45f665d7.jpg)
Par Rick H. - TheExpert cybersécurité chez Squad
De nos jours, des quantités gigantesques d’informations diverses sont générées dont certaines sont sensibles et se doivent d’être protéger. Avec l’arrivée de nouvelles conformités telles que le projet de loi de programmation militaire, la RGPD ou encore PCI-DSS, les entreprises se doivent de s’y soumettre. Pour ce faire, de longs projets doivent être mis en œuvre et il faut parfois revoir tout ou partie de l’architecture en place.
Fort heureusement, des solutions existent pour protéger ces données sensibles tout en respectant ou en évitant ces conformités. Typiquement, PCI-DSS agit principalement sur la manipulation de données de numéro de cartes, donc, si l’on s’arrange pour ne plus manipuler des numéros de cartes à proprement dit mais « autre chose », nous sortons du scope PCI-DSS.
Nous allons présenter rapidement 4 types de protection de données : le chiffrement, le masquage, l’anonymisation et la tokenization.
Le chiffrement
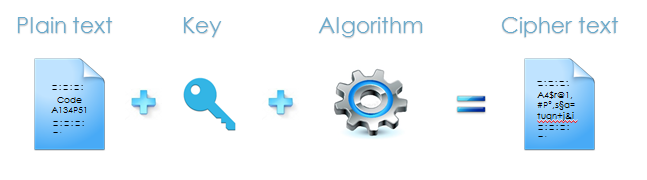
Le chiffrement est la méthode de protection la plus connue. Elle consiste à utiliser un algorithme connu de tous, dit de chiffrement, combiné à une clé, dite secrète. Le but étant de prendre par exemple un texte que l’on appelle « texte en clair », en entrée, et d’en sortir une suite de caractères incompréhensibles que l’on appelle « texte chiffré ». Cette opération, contrairement à l’opération de hashage, est réversible. Cependant, elle ne conserve ni la longueur ni le format initial.
Le masquage
Le masquage consiste, comme son nom l’indique à masquer certains caractères afin d’empêcher de remonter à la source. C’est la méthode utilisée sur vos reçus de ticket de carte bleue, en général, les 4 derniers caractères seulement sont visibles. Le problème étant, vous l’avez deviné, qu’en corrélant la même donnée initiale qui a été masquée plusieurs fois de façon différente, nous pourrons peut-être remonter à la source.

L'anonymisation
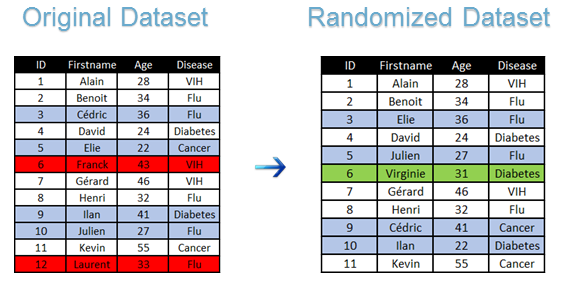
L’anonymisation est une méthode assez vaste sur laquelle on pourrait s’étendre des heures mais je vais simplement me contenter d’en expliquer les bases. Elle se décompose en deux grandes familles que sont la randomisation et la généralisation. Ces deux méthodes ont pour principale ligne de mire le fait de « flouter » les informations. La randomisation va altérer un jeu de données initial (typiquement la liste des employés d’une entreprise avec leurs salaires) en utilisant des méthodes telles que l’ajout de bruit, la permutation ou la suppression. Un exemple de jeu de données randomisé :
La généralisation
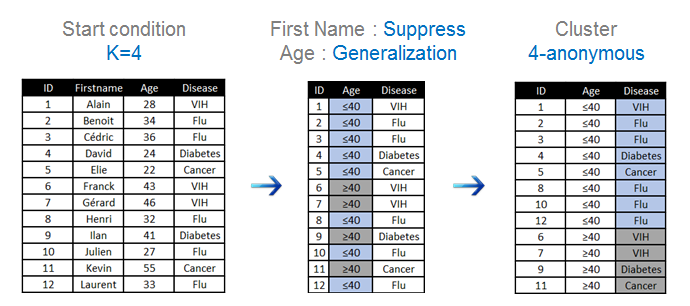
La généralisation, quant à elle, ne va pas altérer le jeu de données initial mais va se contenter de le rendre suffisamment flou pour avoir seulement 1 chance sur X (avec X à définir) de remonter à la source. Les méthodes principalement utiliser sont le k-anonymat et la l-diversité mais ne m’étalerai pas dessus. En voici simplement un exemple d’application :
La tokenization
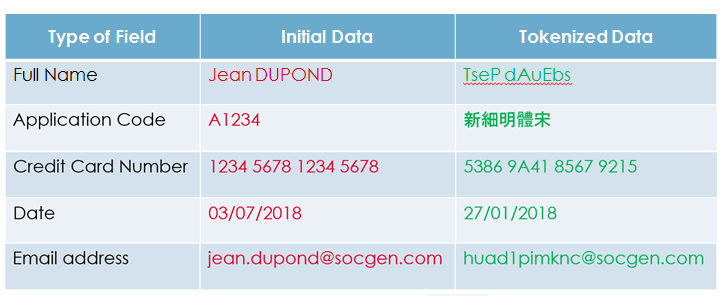
La tokenization est assez récente et innovante. Elle propose de transformer une donnée sensible en un « token » ayant aucune valeur intrinsèque. Elle est réversible et permet également de conserver la longueur et le format initial. Elle est basée sur une méthode de transposition de tables dynamiques afin de ne pas avoir à gérer les clés secrètes et leurs rotations augmentant également la sécurité de l’algorithme dû fait qu’il soit inconnu d’un éventuel attaquant, contrairement au cas du chiffrement où un attaquant n’aurait « que » la clé à trouver. L’exemple le plus classique de tokenization est encore celui du numéro de carte bleue où l’on obtient en sortie un autre numéro de carte bleue de la même longueur mais qui lui n’a aucune valeur intrinsèque. On peut également se contenter de ne protéger qu’une partie de la donnée, dans le cas des dates de naissance ou des mails par exemple. Encore, on peut décider que le format de la donnée initiale ne nous intéresse pas et que l’on souhaite simplement le rendre illisible en remplaçant les caractères par d’autres. En voici quelques exemples classiques :
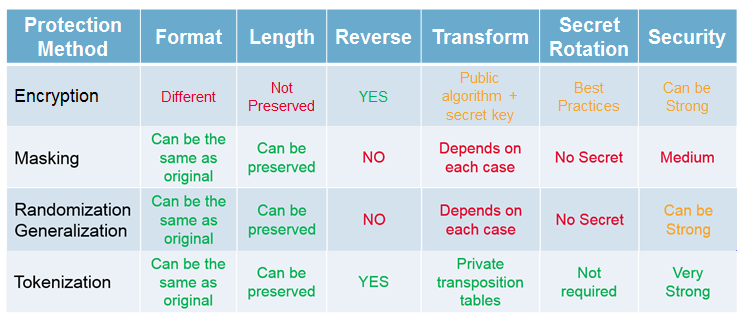
Enfin, pour mieux capitaliser toutes ces informations, voici un petit tableau comparatif entre les méthodes que nous venons de citer :