

Durant les années 2010, plusieurs outils dédiés à l'Infrastructure as code (Ansible, Terraform ou Pulumi notamment) ainsi que des outils d'automatisation (Gitlab-CI, Github-Actions) et de conteneurisation (Docker et Podman) sont apparus sur le marché. Aujourd'hui, ces technologies sont de plus en plus prisées par les grandes entreprises car elles apportent un gain considérable aussi bien en terme de temps que de cohérence et d'efficacité dans la construction de leur infrastructure informatique.
Prenons l'exemple d'un pipeline CI/CD permettant de générer un template de VM de développement. Ce pipeline permet non seulement à long terme de gagner du temps sur l'onboarding de nouveaux arrivants, en leur fournissant directement un template pour déployer automatiquement une VM de Dev avec tous les éléments techniques essentiels déjà configurés (réseaux, certificats, repos internes ...) mais également d'assurer une cohérence et une stratégie saine de développement. En effet, cette stratégie permet d'uniformiser l'environnement de développement des développeurs, ce qui est une pratique fondamentale pour des projets techniques. Pour illustrer ce propos, prenons l'exemple suivant : un développeur utilise une VM Rocky Linux 8.7 alors qu'un autre utilise une VM Rocky Linux 9.2. Leurs environnements de Dev étant considérablement différents, il y a de très fortes chances que du code fonctionne pour le 1er développeur mais pas pour le 2ème et inversement. Par exemple, pour installer le package go, le 1er développeur devra télécharger le binaire de ce package puis l'installer manuellement, alors que le second pourra directement utiliser les repos de sa VM. Evidemment cet exemple est grossier compte tenu des différences notables entre une VM Rocky Linux 8.7 et 9.2, mais ce problème reste le même pour des différences d'environnement bien plus fines (par exemple même version de système d'exploitation mais installations de versions différentes d'un package ou d'un service systemd entre les VM des développeurs). L'uniformisation d'un environnement de développement au sein d'une équipe de Dev est donc très importante, et pour cela la génération de pipelines CI/CD d'infrastructure as code est un atout considérable.
Enfin dernier atout qu'apporte un pipeline CI/CD dans le monde du développement : l'automatisation des tests. Ce point permet de consolider la cohérence et la stratégie de développement à long terme, en réduisant drastiquement les erreurs lors de l'intégration de nouvelles fonctionnalités. Prenons l'exemple suivant : un développeur implémente une nouvelle fonctionnalité dans une application relativement complexe. Une fois qu'il a terminé sa tâche, il vérifie que cette dernière a bien l'effet escompté en testant les différentes parties de l'application qu'il juge impactés par ses modifications. Mais sans pipeline CI/CD, l'application étant relativement complexe, à moins que ce développeur ne maîtrise à 100% l'application (ce qui est très rare), il ne peut s'assurer que ses modifications n'impactent pas des parties de l'application qu'il n'aurait pas anticipées. Avec le pipeline CI/CD, ce cas de figure n'arrivera pas ou du moins bien plus rarement peu importe le profil du développeur, car si ses modifs impactent une partie de l'application qu'il n'avait pas anticipée, alors si les tests du pipeline sont bien écrits, le pipeline plantera et informera directement le développeur du ou des job(s) impacté(s) par ses modifcations.
Autre point majeur expliquant la progression de la recherche de ces compétences : la montée exponentielle du risque cyber ces dernières années. Les entreprises sont aujourd'hui friandes d'automatisation pour se prémunir d'attaques cyber (analyse statique de code, analyse dynamique de code, détection de vulnérabilités, durcissement et sécurisation de système d'exploitation ...). Nous allons nous intéresser ensemble à la création d'un pipeline CI/CD pour améliorer les performances de développement d'un projet durcissant et sécurisant un iso d'une distribution Linux (Rocky Linux 9.4).
Pour ce type de projet, nous verrons ensemble quels atouts apportent un pipeline CI/CD. Pour cela, nous allons dans un premier temps créer un environnement de développement stable et bon marché (via la création d'un cloud privé à l'aide de serveur bare metal d'OVH et de nos propres runners Gitlab). Puis, nous builderons automatiquement notre iso en nous concentrant sur les tâches d'automatisation de construction et de déploiement propre aux pipelines CI/CD. Puis nous verrons ensemble comment déployer automatiquement une VM à partir de l'iso sécurisé généré, et enfin comment tester automatiquement cette VM déployée ainsi que la sécurité de notre code.
Sommaire :
- Configuration de votre cloud privé
- Création de vos propres runners Gitlab
- Tutoriel rapide de création de pipelines via Gitlab CI
- Build automatique de l'iso
- Automatisation de détection des vulnérabilités de code et de conteneurs
- Déploiement automatique d'une VM avec l'iso sécurisé
- Application des tests automatiques via Ansible sur trois VMs, dont celle déployée à partir de l'iso sécurisé
- Conclusion
Configuration de votre cloud privé
Choix du serveur chez OVH et installation de l'hyperviseur Proxmox V8
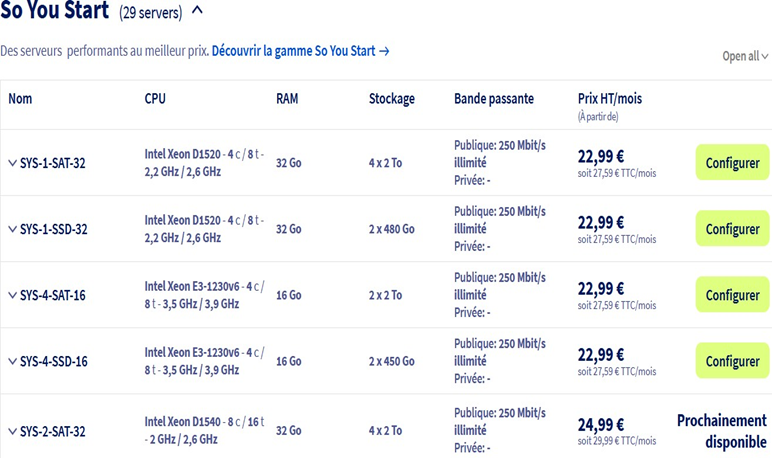
Pour avoir notre propre cloud privé, nous allons utiliser un serveur bare metal chez OVH et y installer l'hyperviseur Proxmox. Pourquoi ? Tout simplement car ce sera la solution la moins chère. AWS et Azure offrent beaucoup plus de services, mais sont bien plus chers. Pour cela, je vous conseille de prendre un serveur bare metal de type "So you start" chez OVH. Il en existe au total 29 aux ressources à peu près similaires et à 27,50 euros par mois sans engagement. Cela peut paraître cher au premier abord, mais ce n'est pas le cas car vous serez libres d'utiliser votre serveur comme bon vous semble et vous ne serez donc pas payés à l'utilisation, ce qui est bien plus élevé. J'ai de mon côté choisi le serveur SYS-1-SSD-32 qui offre 32 Go de RAM, 8 CPU et 2 disques SSD de 480 Go de stockage pour 27,50 euros par mois sans engagement. Pour cela, créez-vous un compte sur OVHcloud, puis allez dans Bare Metal Cloud --> Commander --> Serveur dédié, puis sélectionnez tout en bas de la page les serveurs "Eco" (voir capture d'écran 1) et le serveur "So you start" de votre choix (voir capture d'écran 2).

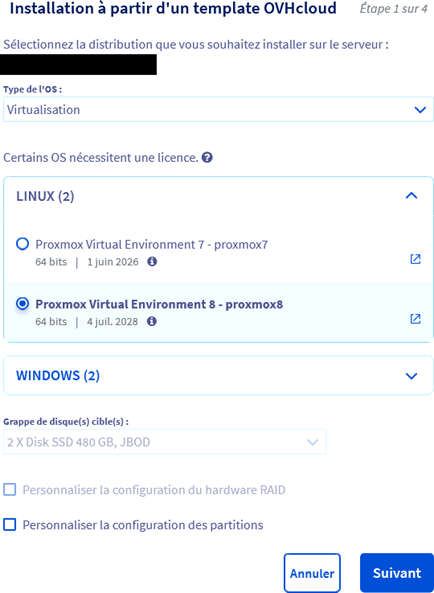
Après l'avoir commandé, OVH vous propose des templates d'installation pour de nombreuses distributions (Alma Linux, Ubuntu, Windows, Rocky Linux ... Proxmox). Nous allons utiliser le template Proxmox 8 pour installer sur notre serveur l'hyperviseur Proxmox 8.

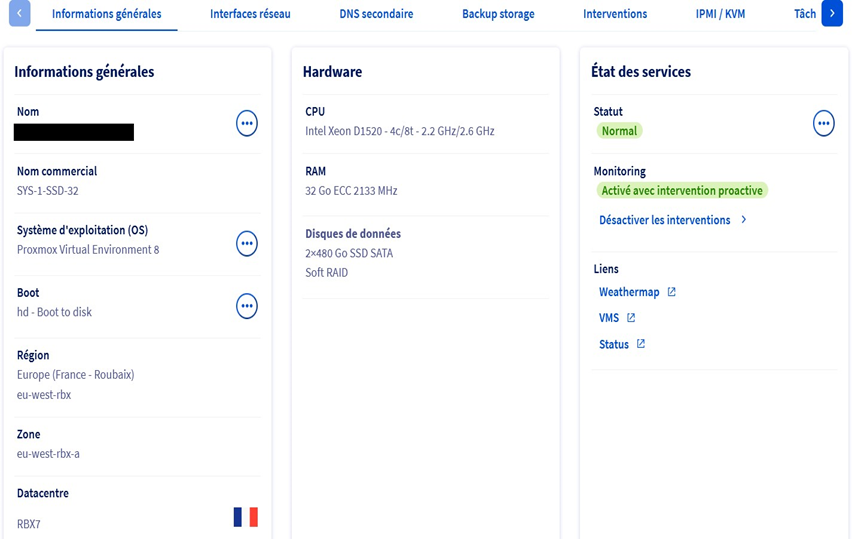
On peut voir que mon serveur OVH a comme système d'exploitation : Proxmox V8, qu'il a bien 32 Go de RAM, 8 CPU et 2 disques SSD de 480 Go, puis qu'il est hébergé dans le datacentre d'OVH de Roubaix.
Configuration de sécurité :
Nous avons donc maintenant notre hyperviseur Proxmox hébergé sur notre serveur, et nous pouvons donc commencer sa configuration. Commençons par quelques configurations de sécurité :
- Changement des ports par défaut de services classiques (par exemple pour les services http, https et ssh : remplacements respectifs des ports 80 par 8080, 443 par 4433 et 22 par 2222). IMPORTANT : attention à bien informer SElinux des changements de ports, sinon Selinux vous bloquera. Pour cela, appliquer en tant qu'administrateur la commande semanage port -a -t service_port_t -p tcp
- new_port_number (par exemple semanage port -a -t ssh_port_t -p tcp 2222 pour informer SElinux du changement de port pour le service SSH)
- Création d'un utilisateur admin pour ne pas utiliser le compte root Sécurisation des connexions SSH :
- Désactiver la connexion via le compte root
- Désactiver la connexion via mot de passe (connexions uniquement possibles via clé SSH)
- Configurer un nombre maximal d'essai pour s'authentifier (5)
Pour effectuer ces actions, connectez-vous en SSH à partir de l'utilisateur admin que vous avez créé, puis modifiez le fichier de config /etc/ssh/sshd_config avec les éléments de la capture d'écran ci-dessous :
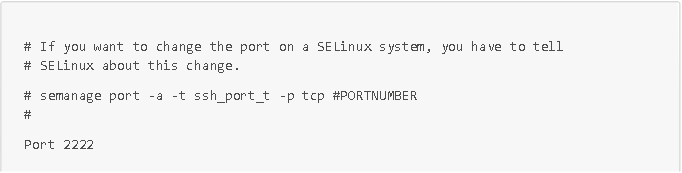
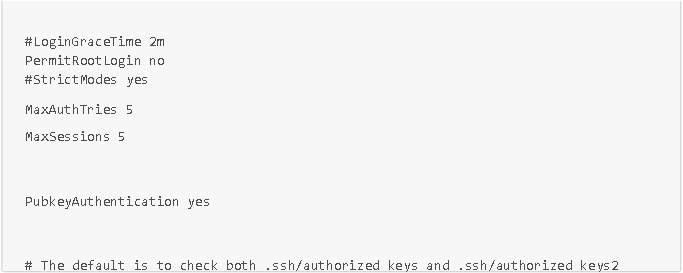
Ces petites configurations de sécurité rapides sont très efficaces pour contrer les attaques par robots.
Configuration réseau
Maintenant que nous avons un peu sécurisé notre serveur des attaques par bot, nous pouvons configurer le réseau. Si notre serveur a son réseau déjà configuré par les équipes d'OVH, ce ne sera malheureusement pas le cas pour les VMs que nous allons créer sur notre hyperviseur Proxmox (hébergé sur notre serveur). Pour cela, nous allons acheter une IP additionnelle (toujours chez OVH), puis créer une VM de routage qui routera le réseau du masque de sous-réseau de cette adresse IP additionnelle sur toutes les VMs que nous allons créer sur notre hyperviseur Proxmox. Nous utiliserons une VM Opnsense comme VM de routage, mais vous pouvez également utiliser si vous préférez une VM PfSense.
Pour commander une IP additionnelle chez OVH : aller dans Bare Metal Cloud --> Commander --> IP
supplémentaire --> IPv4 --> Additional IP. Puis vous pouvez télécharger l'image iso d'une VM Opnsense à l'adresse suivante : https://opnsense.org/download/.
Avant de créer notre VM de routage, nous avons besoin de créer un nouveau bridge réseau sur notre hyperviseur Proxmox, pour avoir une interface LAN et WAN pour notre VM de routage. Pour cela, aller dans proxmox-1 --> network et ajouter le bridge vmbr1 en lui attribuant le réseau ethernet disponible eno4 (voir capture d'écran ci-dessous).
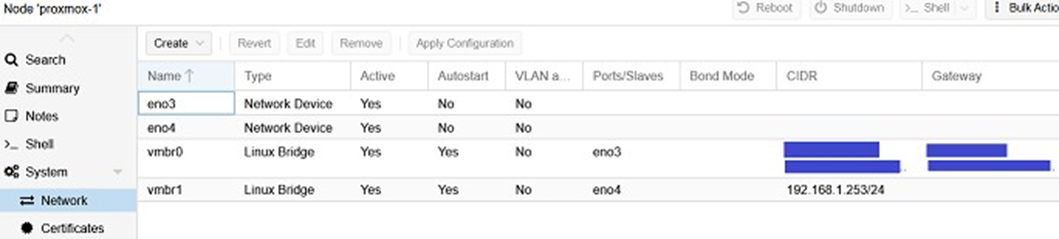
Une fois que ce bridge réseau est créé, nous pouvons créer notre VM Opnsense. Pour cela, créer une VM dans Proxmox en utilisant l'iso des VMs Opnsense téléchargé auparavant et les configurations suivantes :
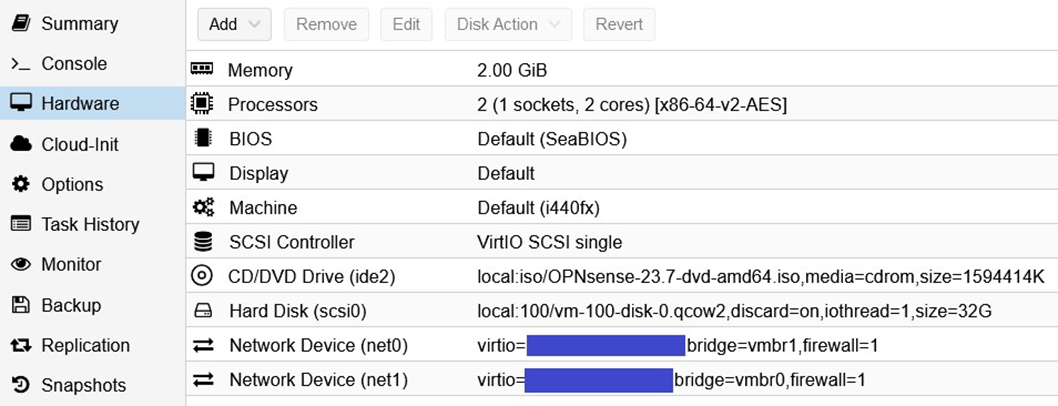
IMPORTANT : pour les configurations réseaux, vous pouvez noter que j'ai masqué les adresses MAC. La complétion de l'adresse MAC du bridge vmbr1 est automatique et sans difficulté (net0), en revanche il est très important pour le bridge vmbr0 (net1) de renseigner manuellement l'adresse MAC de votre IP additionnelle. Pour cela, il vous suffit de consulter sur OVH Cloud les caractéristiques de votre adresse IP additionnelle.
Maintenant que nous avons nos deux network device bien configurés à l'aide de nos 2 bridges (vmbr0 et vmbr1) et de notre IP additionnelle, nous pouvons démarrer la VM Opnsense. La VM va alors commencer ses installations et configurations pour router le réseau en configurant un LAN (local area network) sur le network device net0 utilisant le bridge vmbr1 et un WAN (wide area network) sur le network device net1 utilisant le bridge vmbr0. Elle finira la configuration du LAN, mais pas celle du WAN car elle aura besoin de l'adresse IP additionnelle. Vous devez donc configurer le WAN manuellement. Pour cela, il vous faut vous authentifier à la VM avec les identifiants par défaut qui sont username: root et password: opnsense, puis changer le mot de passe par sécurité avec l'option 3, et assigner votre adresse IP additionnelle à l'interface WAN en utilisant l'option 2. Si tout se passe bien, vous devrez voir votre adresse IP additionnelle définie sur le WAN, et le réseau devrait être activé sur toutes les VMs de votre node Proxmox ayant pour interface réseau le bridge vmbr1.
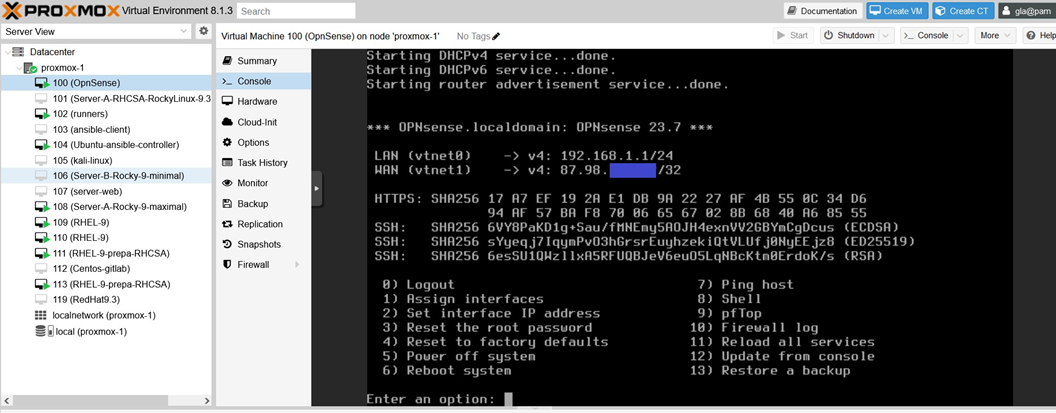
Maintenant que notre hyperviseur Proxmox est prêt et bien configuré sur notre serveur bare metal, nous disposons d'un environnement bac à sable stable sur lequel nous pouvons faire les tests que nous voulons et commencer la création de pipelines CI/CD. Néanmoins avant de créer ces derniers, nous aurons besoin de créer nos propres runners.
Création de vos propres runners Gitlab :
Pour lancer des pipelines CI/CD d'automatisation, Gitlab utilise des runners qu'il fournit directement, mais ces runners sont limités à l'utilisation, plus ou moins importante selon les versions de Gitlab (seulement 200 minutes de CI/CD et surtout 5 Go de stockage pour la version gratuite, 10 000 minutes par mois pour la version premium mais à 29 euros par mois, ce qui pour cette dernière version est largement suffisant pour un particulier mais est assez cher, et est souvent insuffisant pour des grandes entreprises). Vous pouvez retrouver le détail des tarifs des 3 formules de Gitlab à l'adresse suivante : https://about.gitlab.com/fr-fr/pricing/. Pour ne pas être limité sur nos exécutions de pipelines, nous allons donc créer nos propres runners Gitlab sur notre cloud privé. Il existe un grand nombre de runners Gitlab, mais nous ne créerons que les 2 types de runners les plus utilisés, à savoir les runners shell et runners docker. Ce qui sera largement suffisant pour notre projet.
Pour plus de détails sur tous les types de runners disponibles, vous pouvez consulter la page https://docs.gitlab.com/runner/executors/.
Pour disposer de nos propres runners Gitlab, nous allons les créer sur une VM Linux de notre serveur à forte capacité de stockage (200 Go de stockage, VM 102 Runners de mon hyperviseur Proxmox de distribution Rocky 9.2 sur la capture d'écran précédente). Puis une fois que nous avons une VM à capacité de stockage importante, il nous faut créer le runner manuellement sur notre projet dans Gitlab. Pour cela, créer un projet dans Gitlab puis aller dans Settings --> CI/CD --> Runners --> New Project runner de votre projet. Puis ajouter des tags qui vous parlent (ces tags seront utilisés pour appeler vos runners dans les jobs de votre pipeline). Vous pouvez par exemple définir comme tag : proxmox ou my-first-runner. Puis appuyer sur Create runners et votre runner est créé par défaut pour une plateforme Linux et son token d'authentification est affiché (copier ce dernier précieusement).
Nous avons alors notre runner de créé, mais ce dernier n'est pas encore lié à la VM de notre serveur sur lequel nous voulons l'héberger. Pour cela, nous avons 2 méthodes possibles : l'utilisation de la commande gitlab- runner dans un système d'exploitation Linux, ou l'utilisation de l'image docker gitlab/gitlab-runner (ma VM de stockage étant une VM Rocky 9.2, ces 2 méthodes sont possibles pour cette VM). Ces 2 méthodes sont définies ci-dessous :
Via Linux

Via Docker (IMPORTANT : bien utiliser le service docker et non podman)
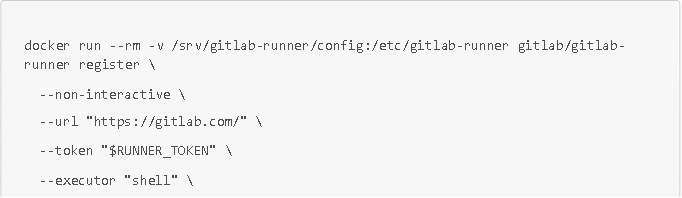
Avec $RUNNER_TOKEN le token d'authentification du runner.
REMARQUE : pour créer un runner docker, il vous suffit d'utiliser les mêmes commandes mais avec l'argument docker pour le paramètre --executor.
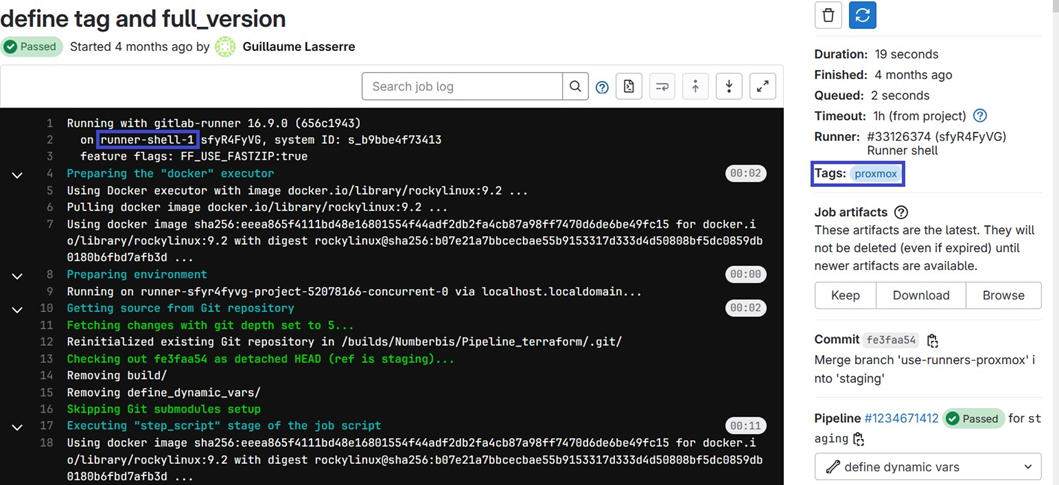
EXEMPLE : voici une exécution d'un job de pipelines CI/CD effectuée à partir de notre propre runner runner- shell-1 et appelé par le job par le tag proxmox (voir encadrés bleus).
Tutoriel rapide de création de pipelines via Gitlab CI
Pour créer un pipeline dans un de vos projet Gitlab, il faut créer un fichier de configuration yaml nommé .gitlab-ci.yml à la racine de votre projet. Ce dernier permettra de configurer notre pipeline. Voici quelques tips pour le configurer.
Ordre des stages et exécution des jobs
Pour définir des ordres d'exécutions de stages, vous pouvez les définir au début du pipeline après la ligne stages : si vous mettez plusieurs jobs dans le même stage, ils s'exécuteront en parallèle (donc en même temps) tant que vous avez suffisamment de runners disponibles pour tous les jobs. Pour plus de clarté et visibilité dans l'exécution de jobs en parallèles (par exemple lorsqu'on atteint plus d'une dizaine de jobs à faire tourner en parallèles), il est conseillé d'utiliser une matrice via la commande matrix.
Variables d'environnement
Pour définir des variables d'environnement, vous pouvez utiliser l'instruction variables : Puis Gitlab met également à disposition de nombreuses variables prédéfinies très utiles comme par exemple la variable
CI_COMMIT_BRANCH donnant le nom de la branche, ou la variable CI_COMMIT_SHA donnant le hash du commit. Vous pouvez trouver toutes ces variables à l'adresse suivante : https://docs.gitlab.com/ee/ci/variables/predefined_variables.html.
Environnement d'exécution d'un job et lisibilité du code
Les jobs s'exécutent dans des conteneurs dont il faut définir les images dans le paramètre image du job. Les runners d'exécution des jobs sont choisis à partir de la variable tags (voir capture d'écran). Sans définition de cette variable, le pipeline s'exécute par défaut avec des runners partagés de Gitlab. Pour améliorer la lisibilité de votre code et de votre pipeline, vous pouvez utiliser des emoji venant du projet Gitmoji. Cela est très utile notamment pour bien différencier les stages.
Build automatique de l'iso
Maintenant que notre infrastructure de test est créée et configurée (cloud privé et runners Gitlab), nous pouvons commencer à automatiser le build de notre iso sécurisé. Pour cela nous allons suivre les trois étapes suivantes :
- Définition d'une stratégie de nomenclature des artifacts et de lancement du pipeline
Définition d'une stratégie de nomenclature des artifacts et de lancement du pipeline
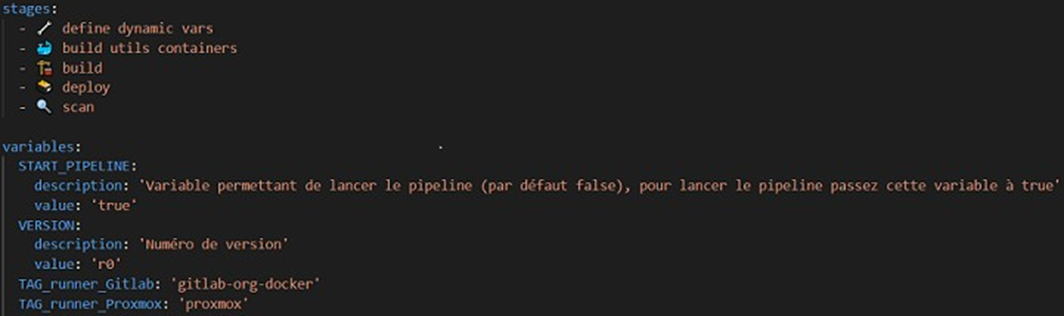
Pour tout pipeline CI/CD, la 1ère étape est de configurer une méthode permettant de définir efficacement et automatiquement une nomenclature pour les artifacts, de manière à être sûr que des résultats d'exécutions ne soient pas écrasés par les résultats d'une autre exécution. Par exemple, sans configuration automatique de la nomenclature des artifacts, les artifacts de chaque exécution auraient le même nom, et donc les résultats de l'exécution N-1 seraient supprimés par les résultats de l'exécution N. Autre élément à prendre en compte : la fréquence d'exécution du pipeline, en effet si sur les branches de production (main ou master) ou de développement commun (qa, develop ou staging), il est important d'exécuter le pipeline automatiquement pour chaque commit, ce n'est pas le cas pour les branches d'évolutions des développeurs, qui ne lancent le pipeline que lorsqu'ils pensent avoir fini leurs évolutions, et non à chaque commit. Il est donc important de configurer ces 2 éléments automatiquement dans notre pipeline. Pour cela, nous allons utiliser un job qui définira automatiquement à l'aide d'un script bash des variables d'environnements selon la branche d'exécution du pipeline puis ajouter une règle à notre fichier de configuration pour définir quand doit être lancé le pipeline.
Règle permettant le lancement d'un pipeline ou non

Cette règle ajoutée dans le fichier .gitlab-ci.yml permet de lancer le pipeline si la variable START_PIPELINE disponible dans l'interface de Gitlab a été passée à True par un développeur qui souhaite tester son code, ou si la branche est une branche de prod ou de développement commun (master, main ou develop).
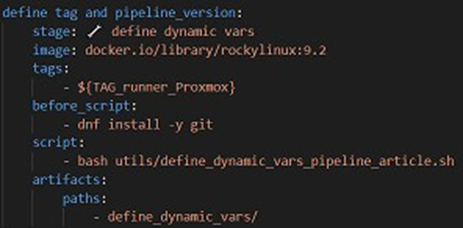
Puis voici le job dans le fichier de config .gitlab-ci.yml ainsi que le script Bash. Vous noterez que ce script permet de définir les variables d'environnement TAG et PIPELINE_VERSION. LA variable PIPELINE_VERSION permettra d'avoir un nom unique d'artifact pour chaque exécution de pipeline et ainsi d'éviter les conflits d'artifacts lors de leurs déploiements dans les repos. Remarque : la variable $VERSION du script est une variable ayant pour valeur par défaut V1_dev, et est configurée de manière à ce que les développeurs puissent renseigner cette valeur directement dans l'interface de Gitlab (s'ils souhaitent avoir un nom d'artifact plus parlant que le nom de leur branche suivi de r1_dev ou surtout qu'ils veulent exécuter plusieurs fois le pipeline sur une même branche de dev).
Script Bash définissant automatiquement la nomenclature des artifacts
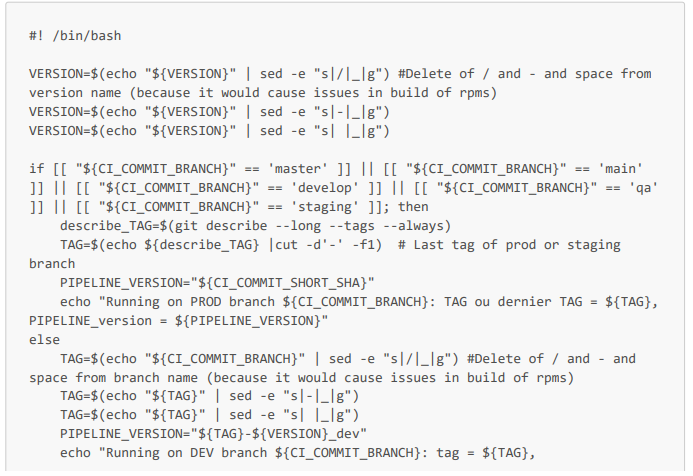
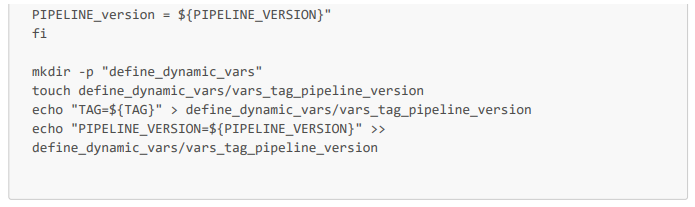
Job du pipeline dans le fichier de config .gitlab-ci.yml

On peut noter que ce job s'applique dans un conteneur rockylinux 9.2 (créé à partir de l'image docker.io/library/rockylinux:9.2), qu'il est exécuté par un de nos runners (de tag ${TAG_runner_Proxmox}), donc directement dans notre serveur, et qu'il enregistre en artifacts le dossier define_dynamic_vars.
Téléchargement de l'iso minimal Rocky Linux 9.4 et modification de ce dernier pour le sécuriser et y ajouter des fonctionnalités
Pour télécharger un iso Rocky Linux 9.4 et le modifier automatiquement pour le sécuriser via un job de pipeline CI/CD, nous allons d'abord dans un conteneur Rocky Linux 9.3 construire un script Bash qui permettra d'effectuer toutes les tâches nécessaires. Puis une fois que nous aurons testé ce script, nous l'exécuterons directement dans un pipeline CI/CD (toujours via Gitlab-CI et avec nos runners).
Commençons donc l'écriture de notre script. La 1ère étape est d'installer les packages nécessaires. Dans notre cas, nous avons trois packages à installer : wget pour le téléchargement de l'iso, genisoimage (equivalent de xorrizo) pour le modifier, et sudo pour la gestion des droits. Après avoir installé les packages nécessaires, nous téléchargeons l'iso à partir de wget. Puis nous pouvons commencer la modification de notre iso. Pour cela, nous devons tout d'abord monter l'iso sur notre système dans un de nos répertoire vide (par exemple /mnt/iso), puis copier tous les dossiers et fichiers de configuration de l'iso monté sur notre répertoire temporaire de travail (variable $WORKDIR du script).
Nous avons alors tous les dossiers et fichiers de configuration de notre iso enregistrés sur notre répertoire de travail (WORKDIR), et nous pouvons alors y appliquer toutes les modifications que nous souhaitons pour y ajouter des fonctionnalités (via l'ajout de rpm par exemple), durcir ses configurations et le sécuriser.
Par soucis de confidentialité, nous ne ferons pas des changements de configurations de sécurité très poussées et nous ne créerons pas de rpms sécurisés, mais cela sera une 1ère étape dans la compréhension de l'approche à adopter pour modifier et sécuriser un iso. Par exemple, nous pouvons appliquer les règles de sécurisation que nous avions effectuées sur notre serveur dans la 1ère partie (changement des ports par défaut pour les services ssh, http et https, et sécurisation des connexions SSH) et ajouter une entrée de montage. Pour cela, nous avons juste besoin d'attribuer les nouvelles config sécurisées aux configs existantes de l'iso et pour notre montage ajouter une entrée dans le fichier /etc/fstab.
Ce qui nous donne le script suivant (que nous appellerons download_and_modify_iso_rocky_9_4.sh dans le job de notre pipeline).
Script Bash complet :

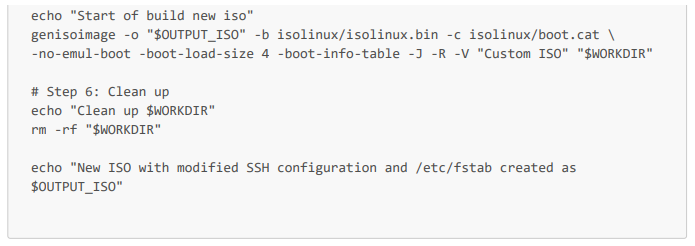
Pour automatiser cela dans notre pipeline CI/CD, il nous suffit simplement d'exécuter ce script (download_and_modify_iso_rocky_9_4.sh) dans un conteneur Rocky Linux 9.3 ou un autre conteneur compatible. Nous pourrions par exemple aussi utiliser un conteneur Red Hat. Voici un job exécutant ce script dans un pipeline Gitlab-CI :

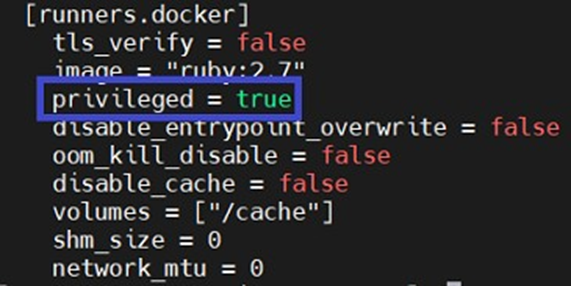
IMPORTANT : attention, pour monter des iso, les conteneurs ont besoin de droit supplémentaire (via l'option --privileged), il faudra donc vous assurer de modifier la configuration de votre runner (fichier /etc/gitlab- runner/config.toml) en passant le paramètre privileged de votre runner à true (voir capture d'écran ci-dessous). Sinon, lors de l'exécution du pipeline, le script plantera dans votre conteneur Rocky Linux 9.3 lors du montage de l'iso.
Déploiement de l'iso sécurisé dans un repo
Idéalement, des solutions de stockage comme Artifactory, Azure datalake ou Amazon S3 sont à privilégier pour des grandes entreprises. Néanmoins, ayant des ressources trop faibles de nôtre côté (32 Go de RAM et 2 disques SSD de 480 Go de stockage) pour monter une instance Artifactory, et Azure datalake et Amazon S3 étant chers, nous allons simplement stocker nos artifacts dans un dossier nommé "repos_artifacts" d'une VM créée sur notre instance Proxmox.
Pour cela, nous configurons une connexion SSH automatique, ce qui nous permet de déployer notre iso automatiquement dans notre repo via transfert SCP. Pour le réaliser, nous devons créer une clé SSH sur la VM hébergeant le repos, puis créer une image docker basée sur une image docker Rocky Linux 9.3 avec une configuration SSH customisée pour que tous les conteneurs créés à partir de cet image docker puissent se connecter automatiquement àla VM hébergeant le repos. Une fois que cette image est configurée, il suffit d'utiliser cette image dans un job de pipeline et appliquer un transfert SCP de l'artifact à déployer. La connexion SSH étant automatique, le transfert SCP l'est également.
REMARQUE : si votre entreprise utilise Artifactory, je vous conseille d'utiliser la librairie requests de Python pour déployer automatiquement vos artifacts.
Nous avons alors un build automatique, ce qui permet non seulement d'accélérer le build des développeurs cyber mais également et surtout de leur fournir un environnement de développement parfaitement uniformisé pour le projet, améliorant drastiquement leur efficacité sur les projets à technicité élevée. J'insiste sur ce point car il est très souvent sous-estimé par les gestions de projets et managers. Pour mieux détailler et comprendre cet atout, le build automatique permet de s'assurer que les développements d'un développeur puissent bien être intégrés à l'application sans créer de problèmes fonctionnels majeurs, et de s'assurer que chaque développeur teste bien ses évolutions sur exactement la même infrastructure (versions et configurations en tout point identique), ce qui permet d'identifier les conflits d'évolutions de développeurs plus rapidement.
L'automatisation du build étant terminée, et les développeurs pouvant l'utiliser pour gagner en efficacité, la prochaine étape à forte valeur ajoutée du pipeline est maintenant l'automatisation des tests. Dans un contexte actuel de risque cyber important, il est important d'automatiser dans un premier temps les vérifications de vulnérabilités de code et de conteneurs.
Automatisation de détection des vulnérabilités de code et de conteneurs
Pour automatiser les vérifications de vulnérabilités au niveau des conteneurs, l'image docker trivy est très utile.
Pour l'utiliser directement dans un pipeline Gitlab CI, vous pouvez utiliser le job suivant en remplaçant la variable IMAGE_NAME_TO_SCAN par l'image docker que vous voulez analyser via Trivy. Trivy vous génèrera alors un rapport de sécurité en artifact (nommé trivy_report.txt pour notre job).

Puis, pour automatiser les vérifications de vulnérabilités de code via des analyses statique et dynamique de code, vous pouvez utiliser Checkmarx ou Sonarqube.
Maintenant que nous avons testé la sécurité de nos images docker via Trivy, nous pouvons commencer les tests fonctionnels. Pour cela, la 1ère étape est d'automatiser dans notre pipeline la création et le déploiement d'une VM avec l'iso sécurisé. Par la suite, nous automatiserons des tests sur cette VM.
Création et déploiement automatique d'une VM avec l'iso sécurisé
Pour réaliser cela, plusieurs langages d'IAC (infrastructure as code) sont possibles (Terraform, Packer, Ansible notamment). Nous allons utiliser de notre côté la ligne de commande qm fournie par l'API de Proxmox. Cette commande nous permettra de créer (ou de détruire) automatiquement des VMs dans Proxmox à partir de scripts. Par exemple le script suivant permet de créer et de démarrer directement dans Proxmox une VM basée sur l'iso sécurisé que nous avons buildé précédemment et ayant pour nom Rocky9.4_securise_demo :
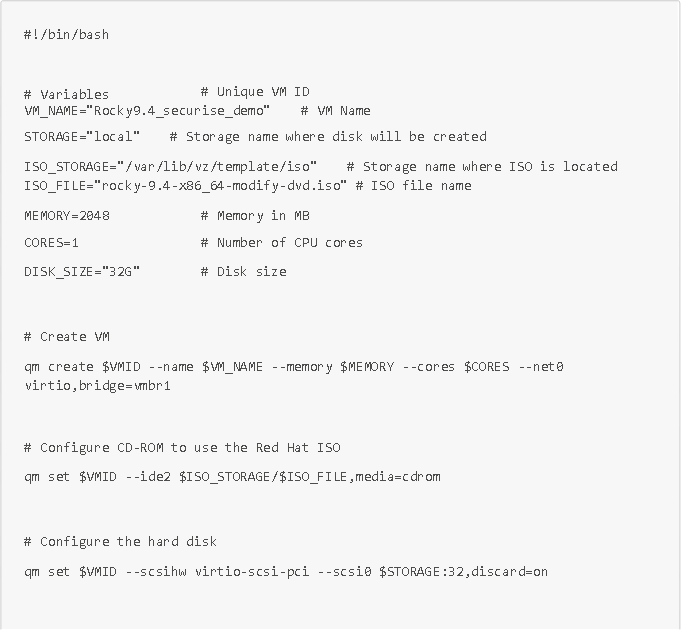

Maintenant que notre VM avec notre iso durci et sécurisé est créée et déployée sur notre hyperviseur Proxmox, nous pouvons automatiser des tests sur cette VM via Ansible.
Application de tests automatiques dans plusieurs VM via Ansible
Nous allons maintenant rentrer dans la partie d'automatisation des tests. Pour cela, en infrastructure as code, Ansible est un outil très puissant de par sa simplicité d'utilisation, sa flexibilité et son idempotence (fait de ne pas exécuter une tâche si la tâche a déjà été effectuée). A partir de ce langage, nous pouvons effectuer une multitude de tests d'infrastructure. Par exemple, nous pouvons vérifier automatiquement l'état de santé du système et ses ressources disponibles, sa sécurité (via la vérification du statut de SeLinux pour des VMs linux par exemple), sa configuration réseau, son backup, ses logs ...
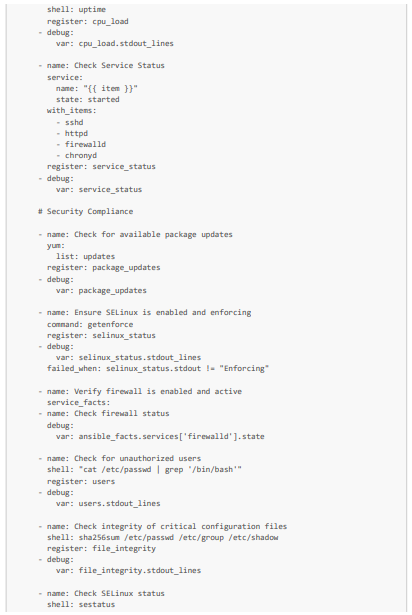
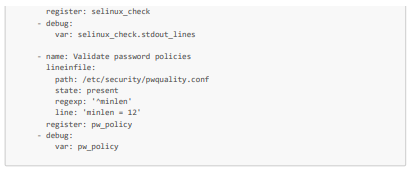
 Nous allons de nôtre côté voir comment automatiser des vérifications sur l'état de santé, les ressources disponibles et la sécurité de trois VMs dont notre VM créée à partir de l'iso durci et modifié. Plus précisément, pour l'état de santé et les ressources disponibles, nous allons vérifier le stockage et la mémoire disponibles, les moyennes de CPU, le fonctionnement des services critiques (httpd et sshd notamment). Puis pour la sécurité, nous allons vérifier que les packages sont à jour, les règles de pare feu, le statut de SELinux, l'absence d'utilisateurs non autorisés, la politique de mot de passe des VMs respecte les standards de sécurité.
Nous allons de nôtre côté voir comment automatiser des vérifications sur l'état de santé, les ressources disponibles et la sécurité de trois VMs dont notre VM créée à partir de l'iso durci et modifié. Plus précisément, pour l'état de santé et les ressources disponibles, nous allons vérifier le stockage et la mémoire disponibles, les moyennes de CPU, le fonctionnement des services critiques (httpd et sshd notamment). Puis pour la sécurité, nous allons vérifier que les packages sont à jour, les règles de pare feu, le statut de SELinux, l'absence d'utilisateurs non autorisés, la politique de mot de passe des VMs respecte les standards de sécurité.
Voici un playbook Ansible (que nous appellerons system_health_and_security_tests.yml) qui permet d'effectuer ces tests :

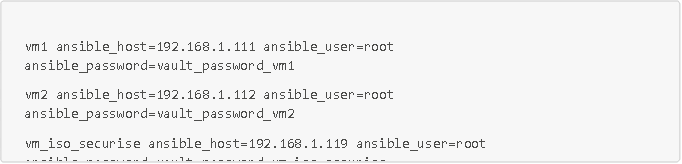
Voici également l'inventaire de notre playbook avec nos trois VMs (que nous appellerons inventory.ini)
Pour exécuter ce playbook :

Conclusion
Ainsi l'intégration des pipelines CI/CD à l'infrastructure as code (IAC) apporte des avantages conséquents au développement de logiciels et aux opérations. En effet, en automatisant le processus de déploiement (à savoir le build uniformisé et la vérification des tests), les pipelines CI/CD garantissent que les modifications de l'infrastructure sont cohérentes, reproductibles et moins sensibles à l'erreur humaine. Cela permet d'améliorer la fiabilité et la stabilité des environnements, ainsi que de réduire les bugs et les risques associés aux configurations manuelles.
En outre, l'utilisation de pipelines CI/CD facilite une livraison plus rapide des changements d'infrastructure, ce qui permet aux équipes de répondre avec agilité à l'évolution des besoins de l'entreprise. Les tests automatisés au sein des pipelines garantissent que tous les changements sont validés avant d'atteindre la production, ce qui permet de maintenir des normes élevées de qualité et de sécurité. Le contrôle de version fondamental dans l'infrastructure as code, associé à la CI/CD, favorise la transparence et la responsabilité, ce qui facilite le suivi des changements et les retours en arrière si nécessaire.
Néanmoins, si les pipelines CI/CD sont incontournables et très performants pour booster la productivité des développeurs avec des environnements de développement uniformisés et des tests automatisés, et pour automatiser la surveillance des systèmes, ils sont souvent fortement liés à des environnements spécifiques ou à des outils particuliers, ce qui peut réduire la portabilité. Par exemple, un pipeline conçu pour fonctionner sur un environnement cloud particulier (comme AWS, Azure ou ici Proxmox) pourrait nécessiter des ajustements pour fonctionner ailleurs. De plus, il est souvent difficile de gérer toute l'infrastructure informatique sous- jacente à partir d'un pipeline CI/CD, comme par exemple la gestion du réseau ou du stockage. Pour pallier à ces deux difficultés, l'utilisation combinée de nos pipelines CI/CD avec Kubernetes est une très bonne approche, car Kubernetes est conçu pour être multi-plateforme et peu sensible par rapport aux fournisseurs de cloud, augmentant donc la portabilité, et peut tracer toutes les configurations de l'infrastructure sous- jacente (comme les configurations réseaux et de stockage par exemple).
Dans l'ensemble, la combinaison des pipelines CI/CD et de l'infrastructure as code permet donc aux organisations de gagner en efficacité, en rapidité et en confiance dans la gestion de leur infrastructure, ce qui conduit à des environnements informatiques plus robustes et plus évolutifs qui favorisent l'innovation continue. Et cette combinaison peut être encore améliorée et renforcée avec Kubernetes.

