

Avec la multiplication des applications utilisées par les entreprises, et par là des différentes identités utilisateurs, il est aujourd’hui primordial d’avoir des outils sécurisés permettant l’identification des employées et la gestion de leurs droits. Les mécanismes d’authentification unique (plus connues sous le terme anglo-saxon « Single Sign-On » ou SSO en abrégés) permettent de répondre à ces besoins de sécurité, en centralisant les authentifications sur un service spécialisé (appelé fournisseur d’identité ou Identity Provider en anglais).
En centralisant les authentifications utilisateurs en un seul endroit, cela permet d’augmenter fortement la sécurité d’un écosystème. En effet, l’entreprise pourra grâce au fédérateur d’identité appliquer des politiques de sécurité (contrôle d’accès, authentification multi-facteur, politique de mot de passe, …) tout en se protégeant en grande partie des attaques de type phishing.
Les applications d’entreprise qui sont fédérées au fournisseur d’identité délèguent l’authentification des utilisateurs à celui-ci. En retour, le fournisseur d’identité leur fournit les informations de l’utilisateur dont l’application à besoin pour créer sa session.
Pour que le SSO fonctionne de manière sécurisée, il existe plusieurs protocoles standards qui sont supportés par la plupart des fournisseurs d’identité open-source ou commerciaux. Voici un petit tour d’horizon des différents protocoles existants.
SAMLv2
Le SAMLv2 est surement le protocole de fédération le plus utilisé historiquement. Il a été standardisé en 2005 par l’OASIS. Il se base simplement sur l’échange de documents XML entre l’application (appelé Service Provider dans le protocole SAMLv2) et le fournisseur d’identité (Identity Provider).
Fonctionnement du SAMLv2
Lorsqu’une application fédérée en SAMLv2 veut authentifier un utilisateur, elle va rediriger celui-ci vers le fournisseur d’identité en mettant en paramètre une SAML Request. Celle-ci est un document XML qui contient principalement les informations suivantes :
- Le nom technique de l’application demandeuse de l’authentification (appelé « entity ID »)
- L’URL sur laquelle l’utilisateur devra être redirigé une fois que le fournisseur d’identité l’a authentifié (appelée « Assertion Consumer Service URL », souvent abrégée en ACS)
- Optionnellement, il peut y avoir une signature de la requête, pour éviter que celle-ci soit modifié par un acteur malveillant entre l’application et le fournisseur d’identité
Une fois que le fournisseur d’identité a reçu la requête de l’application, celui-ci va authentifier l’utilisateur. Pour cela, il pourra se baser sur plusieurs critères (identifiant/mot de passe, jeton Kerberos, notifications mobiles, réutilisation d’une session existante, …).
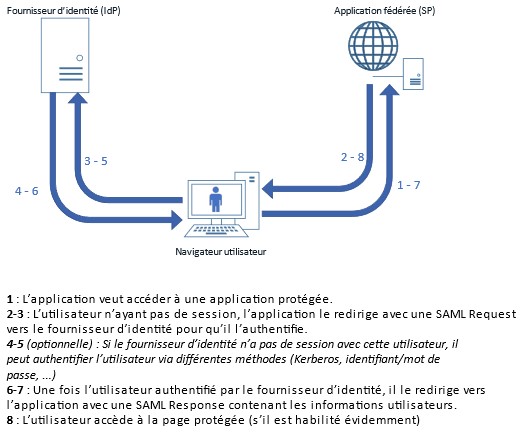
Figure 1: Schéma des échanges lors de l'authentification SAMLv2
Après avoir authentifié l’utilisateur, le fournisseur d’identité va rediriger l’utilisateur vers l’application initiale (en utilisant l’ACS URL qui était présente dans la SAML Request) en y joignant les données utilisateurs dont l’application à besoin. Ces données sont contenues dans un nouveau document XML que l’on appelle SAML Response. Celle-ci contient les éléments suivants :
- Le nom technique du fournisseur d’identité (appelé « entity ID »). Attention, il ne faut pas confondre l’entity ID de l’application avec l’entity ID du fournisseur d’identité. Ce sont tous les deux des noms techniques, mais chaque partie de l’échange à son propre nom technique !
- Un identifiant principal de l’utilisateur (appelé SAML Subject ou NameID)
- Optionnellement, il peut y avoir une liste de plusieurs attributs secondaires de l’utilisateur (adresse mail, nom, prénom, entité, habilitations, …)
- La signature de la réponse SAML. Attention, ici la signature n’est pas optionnelle (contrairement à la SAML Request), car c’est sur cette signature que se base la sécurité du protocole SAML
L’application pourra alors créer une session applicative pour l’utilisateur à partir des informations qu’elle a reçu. L’utilisateur est authentifié.
Sécurité du protocole SAMLv2
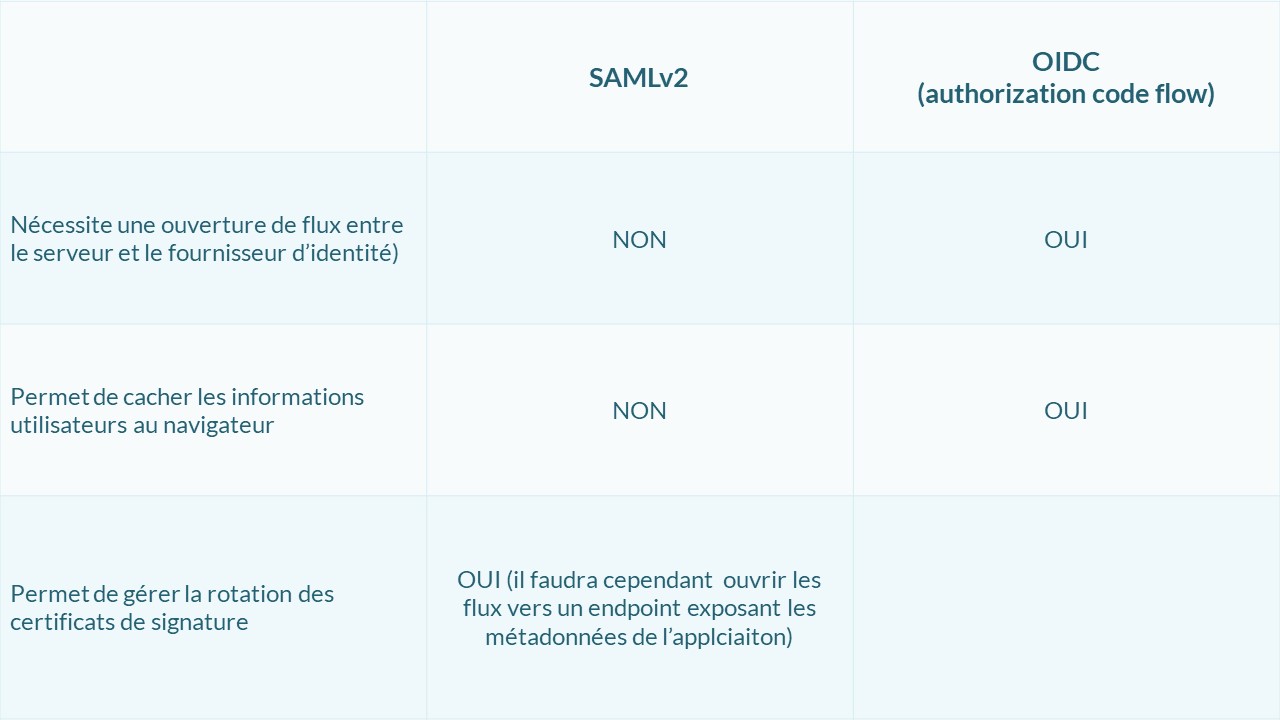
Il est très important de garder à l’esprit que tous les échanges SAML passent par le navigateur de l’utilisateur. Il n’y a donc aucun flux à ouvrir entre l’application et le fournisseur d’identité, le seul prérequis est que les deux soient accessibles par l’utilisateur sur son navigateur. Le revers de la médaille est que ces échanges peuvent facilement être lu voire modifié par une extension du navigateur, ou une fonction Javascript malveillante.
Toute la sécurité du SAMLv2 repose donc sur la signature de la SAML Response. En effet, les applications fédérées au fournisseur d’identité lui font confiance pour lui fournir les informations sur l’utilisateur qui veut s’authentifier. La signature permet de s’assurer que la réponse n’a pas été modifié avant d’arriver à l’application.
Si des informations utilisateurs transmises par le fournisseur d’identité sont confidentielles, il est possible de chiffrer la réponse SAML renvoyés par l’IdP afin que les attributs ne soient pas lisibles. De manière générale, il est conseillé de chiffrer les réponses envoyées à toutes les applications critiques.
OAuth 2.0/OpenID Connect
OAuth 2.0, OpenID Connect, quelles différences ?
Si vous avez déjà travaillé avec des APIs, vous avez très certainement entendus parler du protocole OAuth. Celui-ci a en effet était créer pour permettre la gestion des autorisations d’accès à une ressource par un service tiers. C’est le protocole qui est utilisé par exemple, lorsque vous consentez à autoriser votre client mail (Outlook/Thunderbird) à accéder à votre boite Gmail en ligne. Dans cet exemple, Google, une fois que l’utilisateur a consenti à l’opération, va émettre un jeton d’accès (plus généralement connu sous le nom d’Access Token) valable sur un périmètre précis (appelé « scope »). Le client mail pourra alors utiliser ce jeton d’accès pour faire les actions que l’utilisateur lui a autorisé à faire sur ce périmètre (lire les mails, envoyer des mails, …).
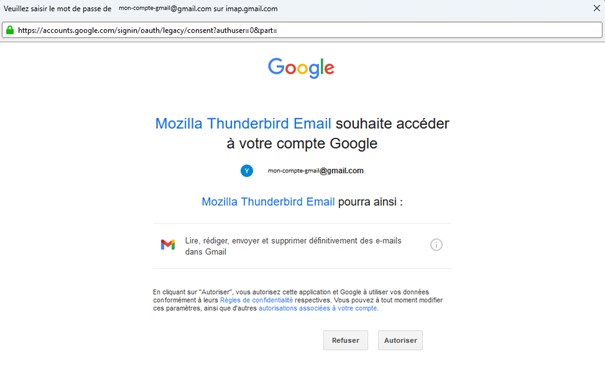
Figure 2 : Exemple où l'on permet à un client de messagerie (ici Mozilla Thunderbird) d'accéder aux mails d'un compte Google
OAuth 2.0 a donc été créé pour des besoins d’accès à des ressources entre applications. L’utilisateur, dans ce processus, s’authentifie dans le seul but d’autoriser ou non ces actions à mener (envoyer des mails, lire le calendrier, …) par une application tierce sur ses ressources. OAuth n’a pas pour vocation à authentifier l’utilisateur pour qu’il puisse accéder à une application. Il ne peut donc pas être considérer comme un protocole SSO.
Pour compléter OAuth 2.0 et lui donner des fonctions d’authentification SSO que l’on souhaite en entreprise, l’OpenID Foundation a introduit un nouveau protocole, l’OpenID Connect. Celui-ci est une extension de OAuth 2.0, qui va rajouter un nouveau jeton (en plus du jeton d’accès), le jeton d’identité (connu sous le nom d’ID Token). Ce jeton d’identité contiendra toutes les informations sur l’utilisateur nécessaire au fonctionnement d’une application, le protocole OpenID Connect pourra donc être utilisé comme protocole de SSO. C’est ce protocole qui est utilisé par des fournisseurs d’identité en ligne, comme France Connect pour se connecter aux sites et applications de l’administration française, ou encore les boutons « Se connecter avec Google », « Se connecter avec Facebook », …
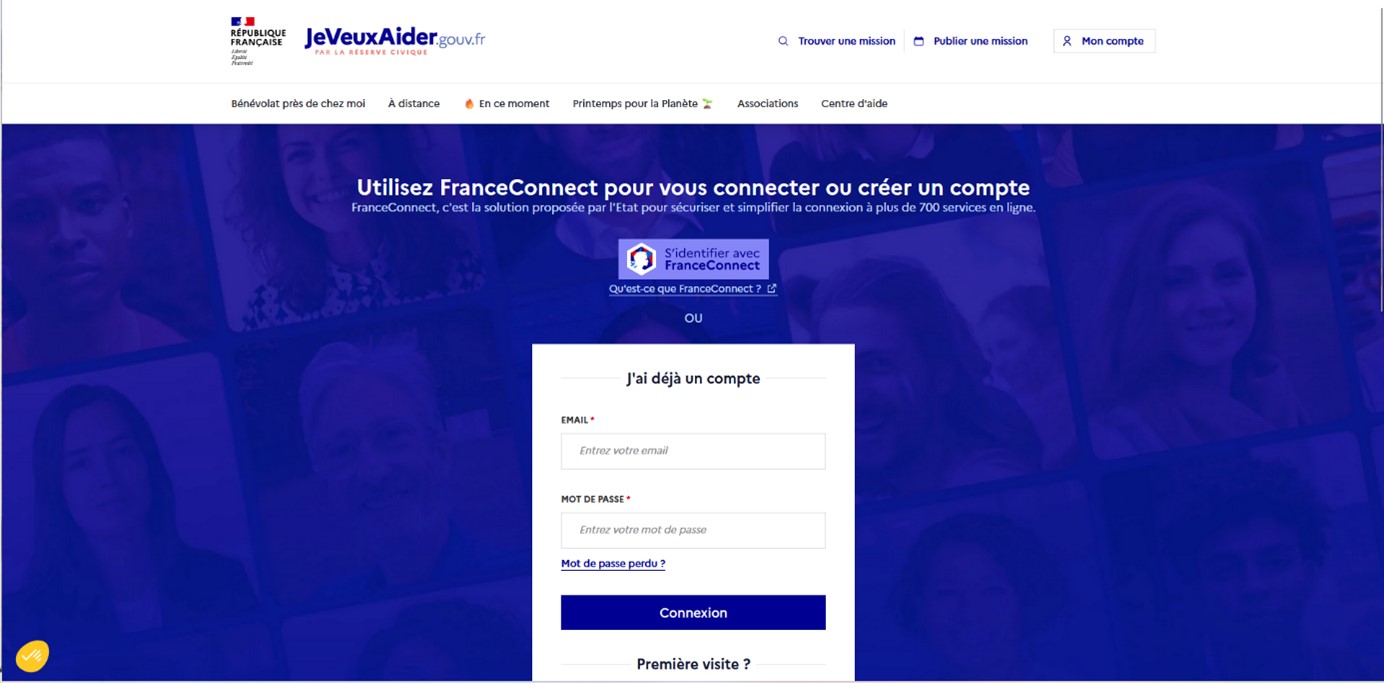
Figure 3 : Exemple où l'on permet à un utilisateur de se connecter à un service (ici jeveuxaider.gouv.fr) soit en utilisant une authentification fédérée (FranceConnect) utilisant le protocole OpenID Connect, soit une authentification locale identifiant + mdp
Fonctionnement de l’OpenID Connect
Le standard OAuth 2.0 définit plusieurs flows, c’est-à-dire différents processus permettant de générer un Access Token. Deux d’entre eux ont été repris par le protocole OpenID Connect :
- Implicit Flow
- Authorization code Flow
L’Authorization Code Flow
L’Authorization code flow est le flux le plus utilisé pour l’authentification utilisateur. Il consiste en 2 échanges client/serveur. Cela commence lorsque l’application demandeuse de l’authentification (appelée « client ») redirige l’utilisateur vers le fournisseur d’identité (appelée Authorization Server), avec quelque simple paramètre dans la requête :
- Le client ID (identifiant unique de l’application)
- L’URL de redirection sur laquelle l’utilisateur sera redirigé après avoir été authentifié par l’Authorization Server
- Le type de flow (grant_type) : ici ce sera « authorization_code »
- Un ou plusieurs scopes (au moins le scope « openid »).
L’Authorization Server va par la suite authentifier l’utilisateur (identifiant/mot de passe, jeton Kerberos, notifications mobiles, réutilisation d’une session existante, …). Une fois authentifié, l’utilisateur est une nouvelle fois redirigé vers l’application fédérée grâce à l’Url de redirection qui a été envoyée en paramètre dans la requête initiale, avec un code à usage unique.
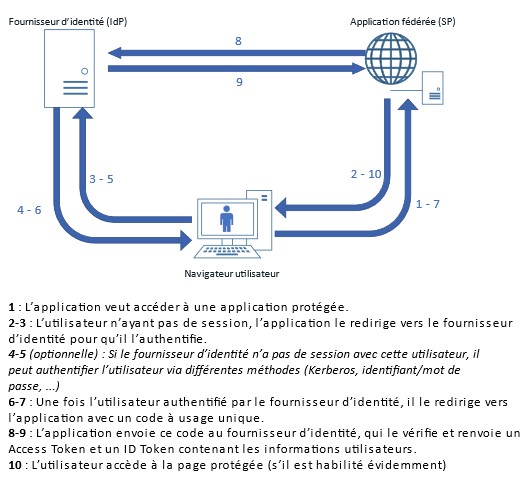
Figure 4 : Schéma des échanges lors de l'Auhtorization code flow (OAuth 2.0/OIDC)
Afin d’obtenir l’Access Token et l’ID Token (dans le cas d’une authentification OpenID Connect), l’application cliente devra ensuite recontacter l’Authorization Server, en faisant un appel API directement vers le fournisseur d’identité, avec en paramètre :
- Le client ID
- Le client secret (un secret que seul l’application cliente et le fournisseur d’identité doivent connaitre)
- Le code reçu lors du premier échange
- L’URL de redirection
- Le type de flow (« authorization_code »)
L’Authorization Server vérifiera que tous ces paramètres sont corrects, et qu’ils sont consistants avec ceux utilisés lors du premier échange, et renverra en réponse 2 jetons, un Access Token (qui pourrait être utilisé par l’application cliente pour accéder à des ressources tierces) et un ID Token (qui pourra être utilisé pour récupérer les informations de l’utilisateur et lui créer une session).
Vous vous demandez peut-être pourquoi est-ce que l’on fait ces 2 échanges client/serveur, dans lequel on récupère tout d’abord un code intermédiaire avant de récupérer le jeton d’identité (ce que l’on veut), alors qu’en SAMLv2 il n’y a qu’une seule redirection.
L’approche de l’authorization code flow ici est d’éviter que des données sensibles (Access Token permettant d’accéder à des ressources applicatives, ID Token contenant des informations privées) ne transitent par le navigateur de l’utilisateur.
En effet, la première étape permettant de récupérer le code est une redirection (se passant donc sur le navigateur de l’utilisateur) et est donc potentiellement interceptable. La deuxième étape consiste en l’envoi du code reçu précédemment, pour obtenir les jetons.
Or, cette étape se fait en « back-channel », c’est-à dire en liaison direct application-fournisseur d’identité. Ceux-ci partagent un secret commun (appelé « client secret ») qui permet d’éviter qu’un attaquant ayant intercepté le code lors de la première phase récupère les jetons avant l’application cliente.
L’implicit Flow
L’implicit flow est une version « raccourcie » de l’Authorization code Flow. En effet, au lieu de faire 2 échanges client/serveur, il ne va faire que le premier. Le fournisseur d’identité n’enverra pas alors de code qui pourront être utilisé pour récupérer dans un second échange les deux jetons d’accès et d’identité, mais il enverra ces jetons directement.
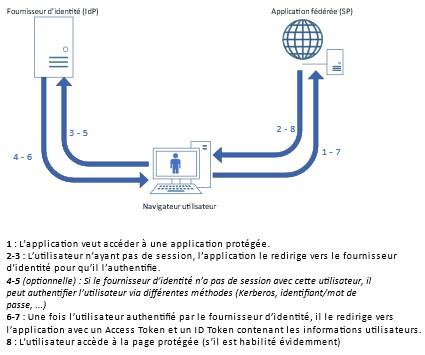
Figure 5 : Schéma des échanges lors de l'Implicit flow (OAuth 2.0/OIDC)
Etant donné qu’il n’y a pas de connexions en « back-channel », l’Implicit Flow est considéré comme bien moins sécurisé que l’Authorization code Flow (tous les données utilisateurs passent par le navigateur. L’Authorization code Flow doit donc lui être privilégié.
Le seul cas où l’Implicit Flow a un intérêt, c’est lorsque la communication ne peut pas être établi entre le fournisseur d’identité et l’application (par exemple si le fournisseur d’identité n’est accessible que via l’intranet de l’entreprise et que l’applications est en SaaS). En effet, dans ce cas la communication en « back-channel » de l’Authorization code Flow n’est pas possible, il faudra donc utiliser l’Implicit Flow.
Qu’est-ce que le PKCE ?
Lors de vos recherches sur le protocole OAuth/OpenID, vous avez peut-être entendu parler de PKCE (pour « Proof key for Code Exchange » qui pourrait être traduit par « Clé preuve pour l’échange du code »).
C’est une extension de l’Authorization Code Flow, qui permet d’éviter qu’un script ayant intercepté le code renvoyé par l’Authorization Server puisse l’utiliser pour récupérer les jetons de l’utilisateur.
En effet, ce type de sécurité est primordial pour les applications dont le code s’exécute directement sur la machine du client (les applications en pur Javascript, React, Angular, ou les applications mobiles/client lourdes). Pour ce type d’applications, le client secret ne peut pas être considéré comme sécurisé.
Le PKCE va simplement générer une chaine de caractères aléatoire, qui sera haché. Lors de la première phase de l’Authorization Code Flaw, l’application enverra le résultat de l’opération de hachage (appelé « code challenge »). Lors de la seconde phase, l’application enverra la chaine de caractère originale (appelé « code vérifier »), que seule lui doit connaitre du fait de la complexité de faire une opération inverse sur un hachage. L’Authorization Server pourra lui vérifier très simplement la validité du couple code challenge/code vérifier.
Ainsi, le PKCE permet à l’Authorization Server de s’assurer que l’application qui a initié l’échange est bien celle qui le termine. C’est pour cela que le PKCE est indispensable pour toutes les applications qui tournent directement côté client, mais plus généralement recommandé pour toutes les applications utilisant les protocoles OAuth 2.0 ou OpenID Connect
Sécurité de l’OAuth 2.0/OpenID Connect
OAuth 2.0 et OpenID Connect repose sur l’échange de jeton (d’Accès ou d’Identité). Ces jetons sont émis au format JWT (JSON Web Token). Ce format est composé de 3 parties :
- L’en-tête, qui comporte les quelques éléments techniques utilisés pour générer le jeton
- Le corps qui comporte les informations utiles du jeton (information utilisateur ou scope accessible par celui-ci).
- La signature cryptographique des 2 premières parties. Cette signature, générée par l’Authorization Server, doit absolument être vérifiée par l’application qui reçoit le jeton. Cela lui permettra d’en valider l’authenticité
Pour faciliter la maintenance des certificats de signature cryptographique, le protocole OAuth définit un endpoint sur lequel l’Authorization Server expose les clés publiques de ses certificats de signature. Ainsi, lors de changement de certificat, les applications pourront récupérer automatiquement les nouveaux certificats, sans de modifications de la configuration de l’application.
WS-Fed
Le protocole WS-Fed (abréviation de « Web Services Federation ») est un protocole SSO introduit par un consortium de grandes entreprises informatiques. Il ressemble fortement au SAML, mais il ne connait pas la même popularité que ce dernier. De nos jours, la seule entreprise qui l’utilise encore à grande échelle est Microsoft, qui l’utilise pour la fédération de sa suite Office, même si Microsoft a tendance à s’appuyer de plus en plus sur OAuth avec Azure AD. C’est pour cela que, à moins d’être un développeur Microsoft (dans ce cas je ne suis pas sûr que cet article vous sois très utile), ce protocole n’est plus vraiment recommandé, le SAML lui est préférable car avec plus de support.
Comparaison des différents protocoles
Tous ces différents protocoles, c’est bien beau, mais la question que vous devez vous poser c’est : lequel est le plus approprié pour mon application ? Nous allons essayer ici de résumer les avantages et les inconvénients de chaque protocole en fonction des différents types d’applications.
Vous n’avez pas besoin d’identifier l’utilisateur
Si vous souhaitez simplement permettre l’accès à une application tierce aux ressources de votre application, vous devez utiliser le protocole OAuth 2.0. Celui-ci n’est pas un protocole de SSO à proprement parler, mais il est fait pour ces échanges de données entre applications. L’utilisateur pourra toujours donner son accord pour autoriser ces échanges.
Vous utilisez une architecture SPA
Si vous souhaitez authentifier un utilisateur mais que vous utilisez une architecture « Single Page Application », comme les applications JavaScript écrite en React.js, Angular ou Vue.js. Ce type d’applications, qui tourne sur le navigateur client, sont bien plus adaptés au protocole OIDC. La grande majorité des frameworks pour ce type d’application supportent d’ailleurs souvent ce protocole quasiment nativement. Il faut noter que dans ce cas de figures, le flow Authorization Code avec l’extension PKCE est obligatoire.
Vous utilisez une architecture MPA
Si vous souhaitez authentifier un utilisateur et que vous utilisez une architecture « MultiPage Application » (avec une logique applicative portée côté serveur), vous avez l’embarras du choix. En effet, vous pouvez facilement trouver des bibliothèques qui vous permettent de mettre en place l’authentification SAMLv2 ou OpenID Connect en PHP, Java, Python, JavaScript, …
Comment choisir dans ce cas le bon protocole ? il n’y a pas malheureusement pas de réponses toutes faites dans ce cas, cela dépendra de plusieurs critères : quel fournisseur d’identité est utilisé dans votre entreprise, les règles mis en en place par les équipes gérant le SSO, ... Les protocoles ont eux-mêmes leurs avantages et inconvénients.
En résumé
Nous avons vu qu’il existe 3 protocoles principaux pour faire de l’authentification unique :
- SAMLv2
- OpenID Connect (à ne pas confondre avec l’OAuth 2.0 qui est un protocole d’autorisation et non d’authentification)
- WS-Fed
Le WS-Fed n’étant pas vraiment utilisé est qu’il peut être remplacé dans tous les cas par le SAMLv2, il est à éviter la plupart du temps.
Du reste, le choix entre le SAMLv2 peut dépendre de plusieurs critères : architecture de l’application, le fournisseur d’identité, … Si vous utilisez un fédérateur d’identité récent, il devrait supporter tous ces protocoles. Si vous voulez apprendre un peu plus sur les différents fédérateurs d’identité, leurs avantages et leurs inconvénients, je vous invite à lire cet article qui compare les solutions d’Okta, de PingIdentity et d’Ilex
Je vous invite fortement à lire la documentation en ligne du fédérateur d’identité que vous utilisez, elle contient en général des exemples précis d’intégration SSO. Également, si vous souhaitez voir des exemples concrets d’implémentation du SSO dans votre langage de programmation ou dans votre Framework, sachez qu’il existe des centaines de projets sur GitHub qui traitent de ces sujets
Cet article vous a présenté succinctement les différents protocoles, il y a bien plus de subtilités sur chacun d’entre eux. Tous ces protocoles étant des protocoles standards, vous pouvez lire leurs définitions publiques pour approfondir vos connaissances. Celles-ci ne sont pas destinées à des débutants, mais elles sont très pratiques dès que l’on sait quoi chercher :
Enfin, la fédération d’identité est un bon outil pour sécuriser l’authentification aux applications d’entreprise, mais elle n’est rien sans politiques de sécurité (authentification forte, contrôle d’accès, évaluation des risques, …) permettant de déterminer finement le besoin de sécurité d’une application et l’expérience utilisateur. Ainsi, une application comme le VPN d’entreprise, bien que pouvant être fédéré à l’IdP, exigera une authentification forte (avec authentification multifacteur), tandis que d’autres applications moins critique (réservations de salles, planning d’équipe, …) pourront utiliser une authentification transparente (utilisant un jeton Kerberos).
Yannis DUHAMELLE
Consultant Cybersécurité

