

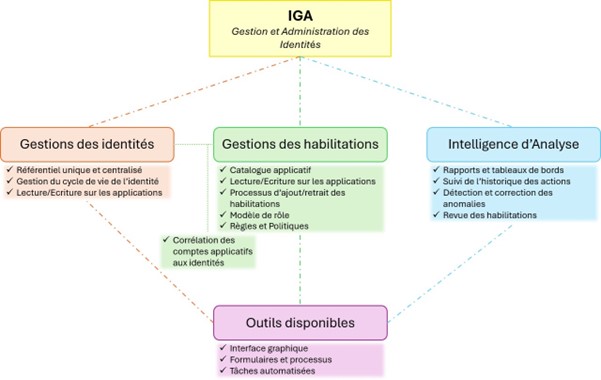
Aujourd'hui je vous propose un aperçu des fonctionnalités principales des solutions de gestion et administration des identités (Identity Governance and Administration - IGA).
Je suis consultante en cybersécurité depuis 4 ans : j’ai travaillé deux ans dans le domaine de l’intégration de solutions d’IGA (plus particulièrement la solution IdentityIQ, de SailPoint) et je travaille depuis deux ans au développement d’une solution de rapports et de tableaux de bords pour les outils d’IAM.
Un aperçu des fonctionnalités des solutions d’IGA
La gestion des identités
L’IGA comprend la gestion des identités et de leur cycle de vie au sein de l’organisation du client.
La gestion des identités passe par la construction d’un référentiel unique centralisé comprenant toutes les identités et leurs informations.
La gestion du cycle de vie des identités passe par la détection des évènements importants et le déclenchement de processus associés.
Enfin, tout cela est rendu possible par des fonctionnalités de lecture et d’écriture sur les applications du SI.
Le référentiel unique et centralisé
La gestion des utilisateurs du SI nécessite de stocker l’intégralité des identités du SI ainsi que leurs informations dans un unique référentiel.
L’objectif premier de ce référentiel est le stockage et le maintien à jour des informations importantes relatives à l’identité.
L’application autoritaire
Pour cela, une application autoritaire est définie.
Une application est dite autoritaire si elle permet la création des identités. Chaque compte lu sur cette application est une identité du SI. La première lecture de cette application crée les identités du système. Par la suite, si un nouveau compte apparaît à la lecture, il déclenchera la création d’une nouvelle identité.
L’application autoritaire est en général l’application des ressources humaines (RH). Il peut y avoir plusieurs applications autoritaires : par exemple si il existe une application RH pour les externes et une autre pour les in- ternes.
La solution d’IGA peut être définie comme la source autoritaire. Cela revient à initialiser la solution en créant les identités au moyen d’une autre application définie autoritaire uniquement à l’initialisation. Puis par la suite, rendre la solution autoritaire en n’autorisant les créations de nouvelles identités que via la solution elle-même (au moyen de formulaires en général).
Le cube identité
L’application autoritaire permet la création des identités. Chaque identité est symbolisée par son cube. Dans le cube, on retrouve toutes les informations connues sur cette identité. Les premières informations sont donc celles présentes dans l’application autoritaire.
Par exemple : on y trouve souvent le nom, le prénom, le mail, le métier, l’unité organisationnelle, les informations personnelles comme le téléphone professionnel et le bureau etc.
Viennent s’ajouter à cela toutes les informations lues sur les autres applications ainsi que les comptes, les habili- tations et les rôles possédés. Certaines informations ne sont pas lues mais calculées à partir d’informations lues.
Ex : le manager peut être calculé à partir de l’unité organisationnelle, le statut actif/inactif dans l’entreprise peut être calculé à partir des dates de début et de fin contrat de l’identité.
Certaines informations peuvent être paramétrées pour être modifiables dans l’interface de la solution. Cela permet la correction ou l’ajout d’informations. Ces actions peuvent être paramétrées pour demander une appro- bation et la solution peut en garder une trace.
Une fois le cube identité complet, ces informations peuvent être écrites sur les applications non autoritaires. Cela permet une synchronisation automatique des informations concernant l’identité entre la solution d’IGA et les ap- plications du SI.
Un cube identité de l’outil IdentityIQ de SailPoint est un bon exemple : on y retrouve bien les informations de l’identité (peu nombreuses dans cet exemple) et on peut voir que des onglets sont disponibles pour visualiser les habilitations (Entitlements), les comptes applicatifs (Application Accounts), les évènements du cycle de vie de cette identité (Events) etc.
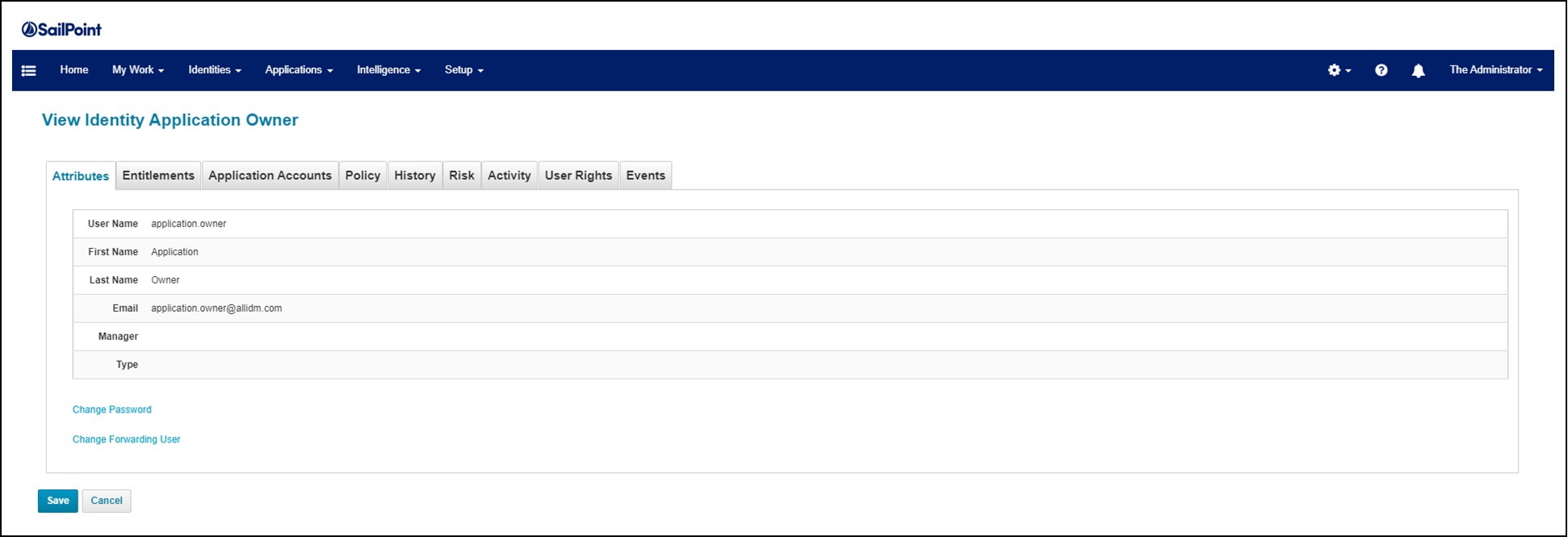
Un cube identité dans IdentityIQ issu de https ://allidm.com/sailpoint-identityiq-create-identity/
La gestion du cycle de vie de l’identité
Une identité d’un SI passe par de nombreuses étapes tout au long de son existence dans le SI. Ces étapes sont significatives et les traquer permet de limiter les anomalies telles que des habilitations non adaptées à la situation de l’identité ou des informations erronées.
La mise en place de processus associés à chaque étape permet une gestion automatique et fluide du cycle de vie de l’identité.
Les évènements déclencheurs

Exemple de cycle de vie d'une identité
Les évènements du cycle de vie de l’identité sont nombreux. Chacun de ces évènements demande une prise en charge des informations et des habilitations de l’identité. Les évènements du cycle de vie de l’identité sont propres à chaque SI, chaque environnement et chaque client.
Pour chaque évènement, on définit une liste de facteurs permettant de savoir qu’une identité vit l’évènement en question.
Ex : une identité peut vivre son arrivée dans le SI quand elle est créée dans la solution : soit via la lecture de l’application autoritaire, soit via une création dans la solution. Mais dans un autre SI, une identité peut vivre son arrivée quand sa date de début de contrat arrive : elle peut donc être créée dans la solution avant son arrivée effective.
Les facteurs à lister peuvent être des changements d’informations ou des dates.
Ex : le manager change, l’unité organisationnelle change alors on détecte une mutation, la date de fin de contrat déclenche le départ de l’identité, la date de fin d’un projet déclenche le retrait des droits et rôles associés. Il peut y avoir plusieurs facteurs pour un même évènement.
La définition précise des évènements et de leurs déclencheurs est une étape importante nécessitant de la part de l’entreprise cliente une grande connaissance des processus déjà existants et beaucoup de réflexion : les effets de bords d’une mauvaise définition peuvent être importants.
Les processus associés aux évènements
La détection d’un évènement déclenche un processus associé. Les processus sont des suites d’étapes permet- tant de mettre en conformité l’identité avec les politiques du SI relatives à l’évènement en question.
La définition de ces processus se fait en fonction des politiques du SI et des processus déjà en place dans l’entreprise. C’est un endroit où la conduite du changement peut être nécessaire si les processus déjà existants ne sont pas satisfaisants en termes de sécurité ou d’efficacité, ou s’ils sont inexistants. C’est également un endroit où le conseil et l’apport de bonnes pratiques est crucial : la création ou la modification des processus peut représenter un challenge pour le client.
Les étapes génériques de ces processus sont la modification et le calcul d’informations, le retrait et l’ajout de droits d’accès et de rôles, l’envoi de notifications, la génération de rapports etc.
Ex : pour une mutation déclenchée par le changement de l’unité organisationnelle (UO) d’une identité, les étapes peuvent être le calcul du nouveau manager en fonction de la nouvelle UO, le retrait des rôles et des droits associés à l’ancienne UO, l’ajout des rôles et des droits associés à la nouvelle UO, la notification des managers et de l’identité concernés et la génération d’un rapport contenant les identités mutées ce jour-là.
Les processus sont une étape importante permettant de préciser les politiques en vigueur et de mettre en place une meilleure sécurité des données.
L’écriture ou provisionning
Après le déclenchement d’un processus suite à la détection d’un évènement du cycle de vie de l’identité, vient le moment de mettre à jour les applications du SI avec les nouvelles informations et habilitations de l’identité.
Cette étape passe par la fonctionnalité d’écriture aussi appelée provisioning.
Les nouvelles informations de l’identité sont écrites sur ses comptes applicatifs. Les nouvelles habilitations de l’identité sont mises a jour dans les applications : certaines sont ajoutées et d’autres sont retirées des comptes applicatifs correspondants.
Finalement, l’identité est à jour, les applications du SI aussi et l’évènement a été traité.
Voici un exemple de vue fonctionnelle de la gestion d’une création d’identité : on y retrouve bien le déclenche- ment du processus par la reconnaissance de l’évènement Création d’une identité puis les étapes nécessaires pour traiter l’évènement en question.
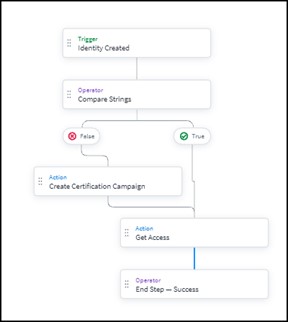
Un processus de création d’identité issu de : https ://documentation.sailpoint.com/saas/help/workflows/workflow-basics.html
La gestion des habilitations
L’IGA comprend la gestion des habilitations (ou droits d’accès) des identités au sein du SI.
La gestion des habilitations passe par la construction d’un catalogue applicatif complet, la gestion des demandes d’accès, la définition d’un modèle de rôles et la création d’une politique précise en termes de droits d’accès.
Le catalogue applicatif
La gestion des habilitations nécessite de connaître l’intégralité des habilitations sur le SI et de les corréler aux bonnes identités.
Cela passe par la connexion de la solution d’IGA aux applications, la lecture des comptes applicatifs et la juste corrélation entre les identités du SI et les comptes applicatifs.
Le catalogue applicatif est constitué des comptes, groupes et habilitations lues sur les applications du SI.
Les connecteurs
Le rôle du connecteur est de faire le lien entre les applications du SI et la solution. Il existe de multiples connec- teurs dont la principale différence est le type d’application à laquelle ils permettent la connexion. Ex : il existe des connecteurs Active Directory, SAP, JDBC, CSV, XML... Il est aussi possible de développer des connecteurs personnalisés pour se connecter à des types d’applications non couverts par les connecteurs par défaut.
Chaque connecteur comprend une configuration leur permettant de se connecter à l’application concernée. Le connecteur permet la lecture et l’écriture des données présentes sur l’application. Certaines applications sont dites connectées ou directes : c’est le cas quand le connecteur lit et écrit directement sur l’application.
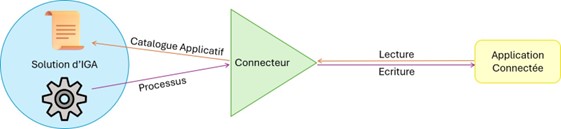
Le rôle du connecteur - Application connectée
Les applications déconnectées ou indirectes ne permettent pas une lecture et une écriture depuis la solution : on passe généralement via des fichiers plats (CSV ou XML). On crée le fichier plat par extraction des données de l’application concernée. Le connecteur permet la lecture du fichier et la création des objets dans la solution. Lorsque des modifications des données de cette application sont nécessaires le connecteur modifie le fichier plat ou en crée un nouveau. L’application se met à jour en lisant le fichier plat le plus récent disponible.
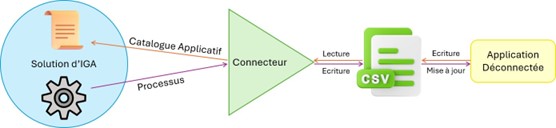
Le rôle du connecteur - Application déconnectée
La lecture des applications
Lors de la lecture des applications, la solution obtient les objets présents sur les applications. Les plus communs sont les comptes applicatifs, les groupes et les habilitations. La solution stocke tous les objets nécessaires : c’est le catalogue applicatif.
La corrélation
Les règles de corrélation permettent d’attribuer chaque compte applicatif à l’identité concernée. Pour cela, des informations présentes sur le compte applicatif sont comparées à ces mêmes informations sur le cube identité.
Si une unique information suffit à faire la corrélation, il s’agit de l’identifiant des identités : ce doit être un attribut unique et personnel, différent pour chaque identité. Ex : le mail, l’identifiant employé ou le trigramme.
On peut également utiliser plusieurs informations qui ensemble permettent l’attribution du compte applicatif sans risque d’erreur.
Ex : le nom, le prénom et l’UO peuvent suffire dans certaines entreprises.
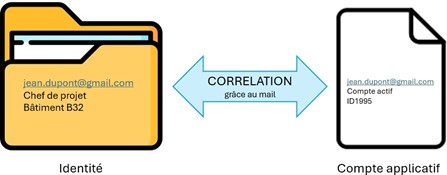
Corrélation sur l’adresse mail
Une étude de la qualité des données et de l’unicité des facteurs de corrélation est souvent nécessaire pour cer- tifier que les règles de corrélation sont adéquates.
Les comptes non corrélables aux identités existantes provenant des applications autoritaires sont à l’origine de la création de nouvelles identités. En revanche, les comptes non corrélables provenant des autres applications restent orphelins.
Les demandes d’accès
La lecture des applications permet de connaître l’état du SI à chaque instant. La gestion des habilitations passe également par la gestion automatique et fluide des besoins des utilisateurs.
Les demandes d’ajout ou de retrait d’accès peuvent être motivées par des évènements prédéfinis. Un évène- ment déclenche alors un processus qui comprend l’ajout et le retrait d’habilitations. Ex : les évènements de cycle de vie de l’identité nécessitent souvent l’ajout et le retrait de droits d’accès. Lors de la mutation d’une identité dans l’entre- prise, les accès correspondants à son ancien poste sont retirés et ceux correspondants à son nouveau poste sont attribués.
Il est également possible de donner une durée définie à l’attribution des habilitations.
Ex : Au début d’un projet, les habilitations nécessaires sont attribuées et la date de fin du projet est renseignée pour que les habilitations soient retirées automatiquement.
Enfin, les utilisateurs du SI peuvent faire eux-mêmes des demandes d’ajout et de retrait de droits d’accès. Les processus automatisés couvrent une grande partie des besoins des utilisateurs et leur objectif est de minimiser les demandes supplémentaires. Les cas particuliers sont pris en charge via les demandes unitaires faites par les utilisateurs dans la solution. Un processus dédié est défini pour gérer ces demandes. Ex : les utilisateurs ont accès à un formulaire leur permettant de demander l’ajout ou le retrait d’accès. Quand une demande est faite, le processus d’attribution ou de retrait comprend généralement des approbations par le manager et le gestionnaire de l’application concernée. Une fois le processus terminé avec succès, les habilitations peuvent être attribuées et les applications sont mises à jour.
La définition des processus et formulaires liés aux demandes d’accès est très personnalisable et doit être ré- fléchie en détail. Les utilisateurs peuvent faire ces demandes directement depuis l’interface de la solution, pour eux-mêmes et pour les collaborateurs qu’ils managent. Les demandes d’accès peuvent être paramétrées pour que des champs comme commentaires, date de début et de fin d’attribution, justificatif et autres soient remplis par le de- mandeur. Aussi, les formulaires peuvent être paramétrés pour afficher au demandeur les informations importantes à propos des accès telles que description, rôles dont il fait partie, risque associé etc.
Un formulaire simple de demande d’accès de l’outil IdentityIQ de SailPoint est un bon exemple : on y observe le premier onglet d’une demande d’accès pour soi-même. Il y a un onglet pour demander un ajout d’accès et un autre pour les retraits d’accès. Les accès à l’écran sont des habilitations et un rôle. On voit des informations les concernant. Le second onglet est un onglet de revue de la demande pour vérifier qu’elle est correcte avant de la soumettre.
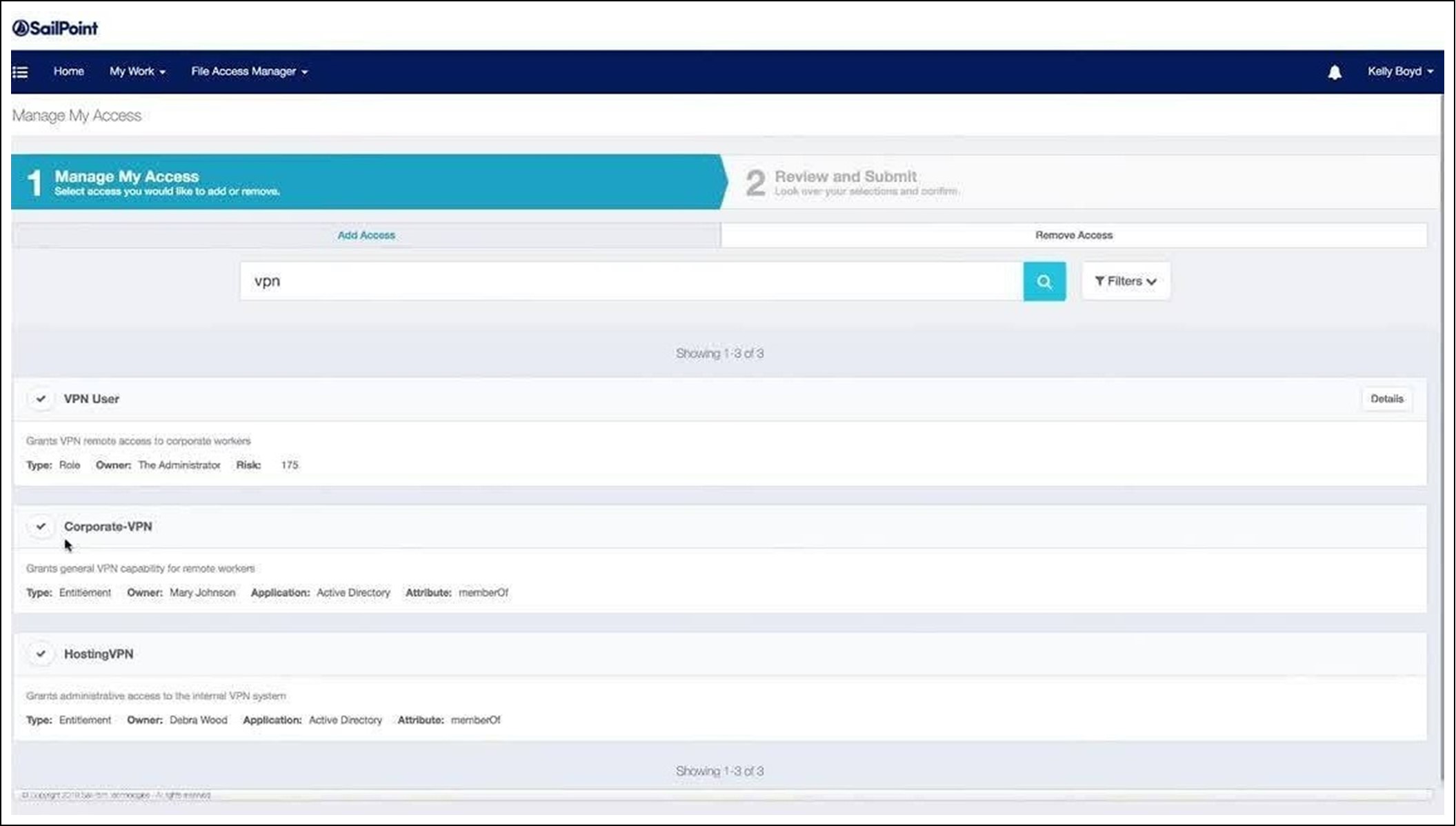
Un formulaire de demande d’accès dans IdentityIQ issu de IdentityIQ Access Requests par SailPoint Technologies sur YouTube.
Le modèle de rôles
Les rôles sont des ensembles de caractéristiques réunissant des identités et donnant droit à des habilitations. La définition de rôles permet la simplification de l’attribution des droits d’accès et de leur relecture par la suite.
La définition du modèle de rôles peut être réalisée par les collaborateurs eux-mêmes : on demande à chaque manager de réunir les habilitations nécessaires pour travailler dans son équipe. Cela crée un modèle de rôles selon les métiers et les UO.
Les solutions d’IGA possèdent généralement une fonctionnalité d’extraction de rôles qui permet de définir les rôles observables à partir du catalogue applicatif corrélé au référentiel des identités. La solution identifie elle-même les points communs entre les identités possédant un même ensemble de droits d’accès.
Le modèle de rôle est un atout pour une solution d’IGA performante et sûre.
- Les utilisateurs se voient attribués un jeu d’accès cohérent sans avoir à faire de demande.
- La compréhension des accès est simplifiée : le rôle a un nom et une description clairs, contrairement aux multiples accès techniques qu’il comprend.
- Les demandes d’accès sont plus simples à réaliser et à approuver : un rôle clair plutôt qu’une liste d’accès indéfinie.
- Le risque de demander et d’obtenir des droits non nécessaires est diminué.
Les différents types de rôles
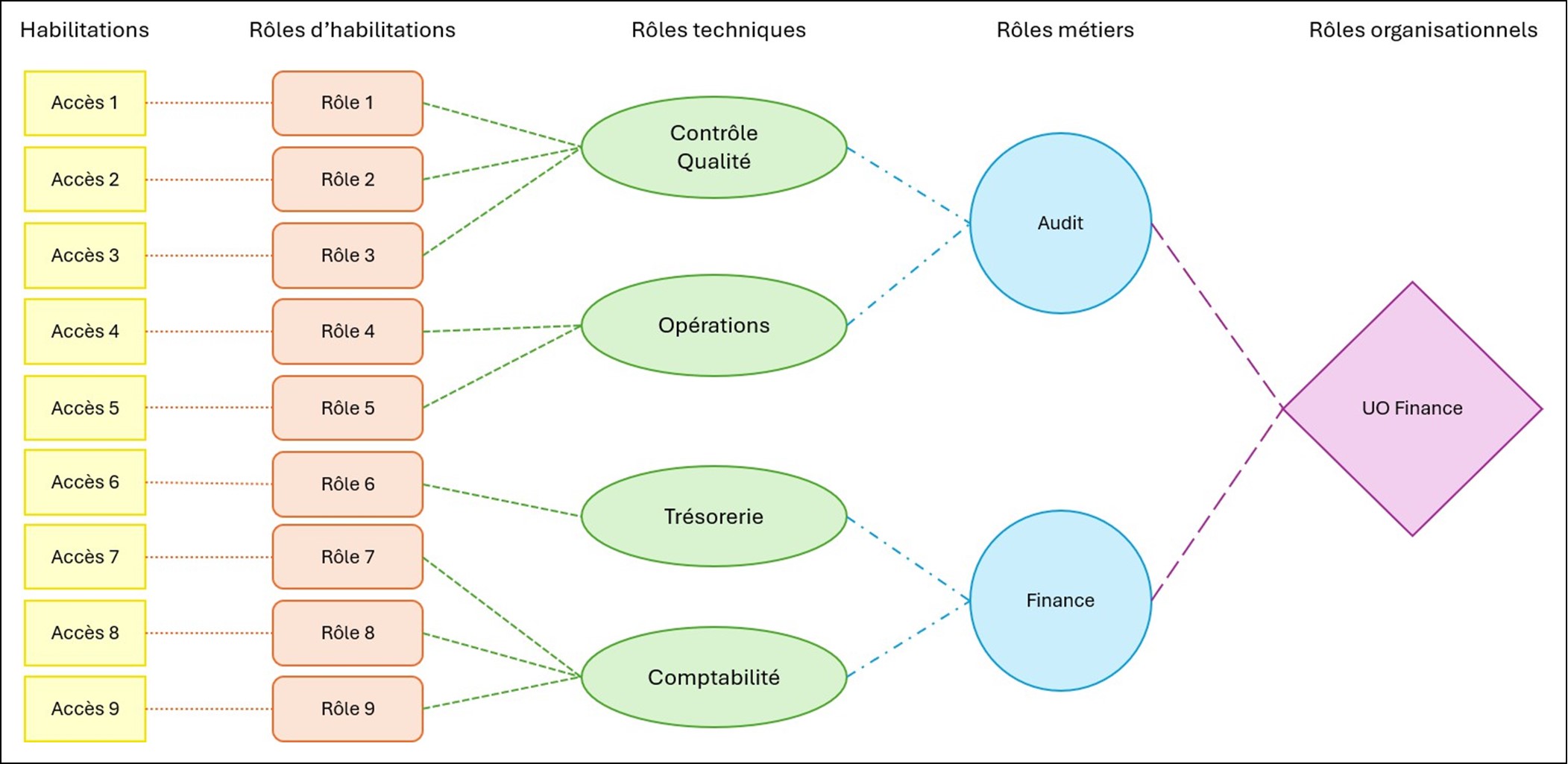
Un exemple de modèle de rôles pour l’UO Finance
Une matrice de rôles complète possède plusieurs niveaux.
- Les rôles d’habilitations (en orange) associent un droit d’accès à sa fonction
- Les rôles techniques (en vert) associent un ensemble de rôles d’habilitations à un besoin technique
- Les rôles métiers (en bleu) associent un ensemble de rôles techniques à un métier ou à une tâche caractéristique d’un métier
- Les rôles organisationnels (en violet) associent un ensemble de rôles métiers à une UO
Les règles et politiques
Une fonctionnalité des solutions d’IGA est la possibilité de définir des règles et politiques pour assurer la sécurité du SI.
Les mécanismes comme la séparation des tâches (Segregation of Du- ties - SoD) permettent de vérifier automatiquement la cohérence des droits et accès avec les règles en vigueur et de signaler les anomalies. La SoD repose sur des associations de droits, d’accès, de comptes qui sont inter- dites. La solution peut empêcher ces associations d’avoir lieu, en interdisant une demande d’accès si elle n’est pas compatible avec les accès déjà possédés.
Des tâches automatiques pour relever les violations de ses règles sont mises en place. Si une règle est enfreinte, des notifications peuvent être en- voyées, des audits sont déclenchés pour garder une trace de l’évènement et des processus peuvent être lancés pour corriger l’anomalie.
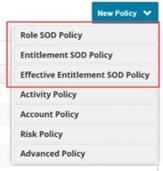
Les types de politiques issus de https ://community.sailpoint.com/t5/IdentityIQ-Wiki/Separation-of-duties-SoD-best- practices-in-IdentityIQ/ta-p/178004#toc-hId–192551779
L’intelligence d’analyse
La partie intelligence d’analyse repose sur plusieurs nécessités :
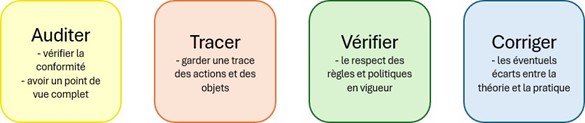
Les besoins d’analyse en IGA
Au sein d’une solution qui centralise l’entièreté des identités et des applications, des fonctionnalités comme les audits, les rapports et les recherches permettent d’avoir une vision claire du SI et de garder un historique des actions et de l’état du SI.
Le respect des politiques en vigueur dans le SI est assuré par des fonctionnalités de détection et de correction des anomalies.
Les utilisateurs peuvent également relever et corriger d’éventuelles anomalies lors des revues des accès.
L’analyse des données
Des outils tels que la génération de rapports, de tableaux de bords et les moteurs de recherches sont disponibles dans les solutions d’IGA pour aider les administrateurs de ces solutions à gérer le SI au mieux.
Les rapports et les recherches
Les rapports d’audit sont des rapports simples, informatifs et concis. Leur écriture est déclenchée par une liste d’actions prédéfinies que le client souhaite tracer. Ex : l’action de redémarrage de la solution peut lancer un rapport d’audit dans lequel on retrouvera l’heure du redémarrage et le temps nécessaire. On peut également paramétrer des rap- ports d’audit pour chaque création d’identité avec l’heure, la date, les informations de l’identité en question et la source.
Les rapports spécifiques sont plus détaillés, complets et complexes. Ils sont paramétrés pour répondre aux besoins en information du client et pour être exportés. Ils peuvent être créés au besoin ou paramétrés pour être générés régulièrement. Ex : les comptes sur une application dont les licences sont payantes peuvent faire l’objet d’un rapport spécifique, on pourrait y trouver des colonnes telles que les noms et prénoms des identités concernées, la date de création et de dernière utilisation de chaque compte ainsi que les droits associés.
Les rapports offrent une multitude de possibilités et les plus pertinents dépendront du contexte et des besoins du client.
Les recherches avancées et personnalisées permettent la recherche d’objets dans la solution et fournissent un grand nombre d’informations. Les recherches sont paramétrées simplement depuis l’interface graphique par le client et permettent d’avoir une vue d’ensemble rapide des identités, des accès et des habilitations présents dans la solution. Des recherches bien paramétrées peuvent donner lieu à l’établissement d’un nouveau rapport.
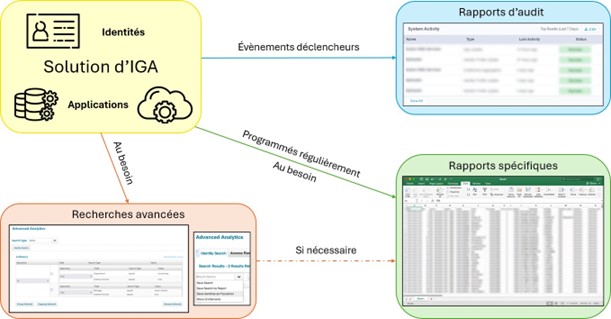
Les fonctionnalités d’analyse de données dont trois images issues de IdentityIQ de Sailpoint
La détection et la correction des anomalies
En cas d’écart avéré entre la théorie et la pratique, le système doit être capable d’identifier les anomalies, de lancer l’alerte et de régler le problème ou de permettre aux utilisateurs de le régler rapidement.
La détection
Des alertes peuvent être mises en place lorsque des anomalies ont été repérées par la solution d’IGA. Si ces alertes sont à destination des utilisateurs, des notifications sont affichées ou des mails sont envoyés. S’il est prévu que la solution gère ces anomalies, ces alertes seront les déclencheurs de processus.
Les deux solutions peuvent être utilisées conjointement : notification des utilisateurs et déclenchement d’un pro- cessus dédié.
Des rapports d’audit peuvent être générés par ces alertes pour garder une trace de l’évènement.
La correction par la solution
Si les anomalies repérées sont anticipables, des processus sont définis pour y remédier automatiquement, rapi- dement et sans intervention des utilisateurs du SI. Le client doit définir les étapes clefs pour pallier chaque alerte. Cela permet à la solution de gérer elle-même sa conformité aux règles en place. Aussi, les anomalies pouvant re- présenter des failles de sécurité pour le SI sont remédiées sans attendre et la sécurité du SI est préservée.
Ex : on se place dans un SI où il a été défini que les mots de passe doivent être changés tous les 3 mois. La solution d’IGA lance une alerte si le mot de passe d’un utilisateur est vieux de plus de 3 mois. Le processus peut être de demander systématiquement un autre facteur d’authentification (réponse à une question, code envoyé par mail ...) à l’utilisateur quand il tente de se connecter puis de rendre obligatoire le changement du mot de passe dès qu’il est authentifié sur la solution. Ainsi, la politique des mots de passe de la solution est respectée et l’alerte ’Mot de passe trop vieux’ est traitée directement par la solution elle-même.
La correction par les utilisateurs
Les utilisateurs de la solution peuvent également régler certaines anomalies du SI. Si une intervention humaine est nécessaire au traitement d’une alerte, des formulaires peuvent être affichés aux utilisateurs responsables pour obtenir les directives ou informations nécessaires.
Quand l’anomalie est un cas particulier inédit ou qu’aucun processus ne peut être généralisé pour résoudre ce problème, les utilisateurs responsables seront notifiés et corrigeront l’anomalie à la main.
Ex : Les comptes des applications non autoritaires qui ne sont pas corrélables aux identités du SI se retrouvent orphelins. Les utilisateurs responsables des applications concernées peuvent alors réconcilier ces comptes avec les identités qui les possèdent.
Si le cas particulier mis en évidence par l’anomalie peut se reproduire, une nouvelle règle sera définie. Si une erreur humaine est la source de ce cas particulier, l’anomalie sera traitée puis l’alerte sera archivée.
Les recertifications
Une recertification permet aux personnes compétentes de vérifier que les accès, comptes ou rôles accordés sont les bons et de révoquer ceux non adéquats.
Le cadre
Une campagne de recertification se définit par son cadre : qu’est-ce qui est revu ?
Il est possible de revoir les comptes, les habilitations et/ou les rôles des identités. Une recertification peut porter sur une ou plusieurs applications du SI. Les identités incluses dans la recertification peuvent être identifiées par une caractéristique commune. Les possibilités sont infinies.
Ex : une re certification des accès notés comme sensibles se fera sur toutes les identités possédant au moins un accès sensible. Toutes les applications qui proposent des accès dits sensibles seront concernées.
Les approbateurs
Une recertification se définit également par ses approbateurs : qui revoit ?
Les choix fréquents sont les managers des identités et/ou les responsables des applications concernées. Il est pos- sible de choisir que la recertification demande plusieurs approbations.
Ex : une recertification peut demander d’abord l’approbation du manager puis celle du responsable de l’application. Les approbations peuvent également être déléguées, c’est-à-dire que l’approbateur désigné peut choisir de deman- der à une autre identité d’approuver l’accès en question. C’est utile dans le cas de managers qui ne connaissent pas un périmètre en particulier et préfèrent demander au responsable du projet d’approuver l’accès.
Les conséquences
Enfin, une campagne se définit par ses conséquences : que se passe-t-il ? Les accès non revus après la date de fin de la recertification peuvent être retirés, notés comme désapprouvés ou notés comme non-revus. Les accès désapprouvés peuvent être retirés dès que l’accès est revu ou à la fin de la recertification. Ils peuvent être notés comme désapprouvés mais laissés aux identités en attendant qu’un responsable les retire lui-même.
La criticité des objets revus lors de la recertification permettra de définir les actions à mettre en place.
Les personnalisations
Des notifications par mails sont généralement envoyées lors des recertifications. On notifie les approbateurs du début de la campagne et on les notifie régulièrement qu’il leur reste des objets à revoir tant qu’ils n’ont pas terminés.
Des options fines comme les commentaires, les dates de révocations, les approbations par lots, etc. permettent de définir des campagnes de recertifications au plus près du besoin du client. Des politiques peuvent être mises en avant lors des recertifications.
Le principe du moindre privilège peut être mis en avant lors de la recertification en affichant clairement quelles habilitations détenues ne semblent pas indispensables à l’identité en fonction de son métier, son UO et ses projets en cours. Les approbateurs décideront ensuite de laisser ces habilitations si elles sont nécessaires ou de les révoquer. Le principe du besoin d’en connaître peut également être mis en avant en rappelant aux approbateurs que seules les habilitations réellement utiles à l’identité doivent être conservées. Le fait de pouvoir avoir une habilitation car son métier, son UO ou ses projets en cours le permettent ne suffit pas à accorder une habilitation. Les réunions d’information et les mails de notification peuvent permettre de rappeler aux approbateurs ces bonnes pratiques cruciales.
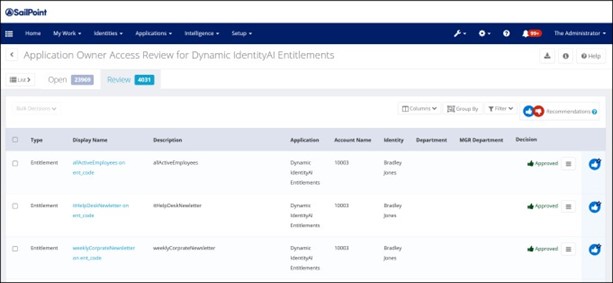
Exemple de revue d’accès
Les outils à disposition
Quelques fonctionnalités très utiles sont disponibles pour permettre aux solutions d’IGA de s’adapter aux besoins des clients et de s’intégrer dans la vie de l’entreprise.
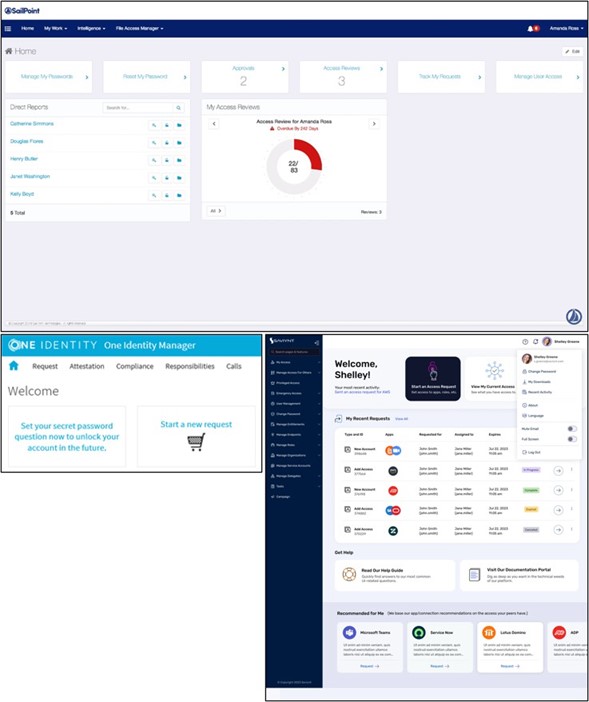
L’interface graphique
L’interface graphique des solutions d’IGA est personnalisable pour correspondre à la marque du client : les codes couleurs, les logos, les polices sont à définir avec le client pour coller au plus près de sa charte graphique habituelle et pour que l’outil se fonde dans l’environnement du client.
L’interface graphique est également personnalisable en termes d’affichage, de raccourcis et de fonctionnalités. Les menus déroulants, les raccourcis, les informations présentent sur la page d’accueil sont à définir avec le client. La page d’accueil doit être intuitive, facile à utiliser et à comprendre pour que la solution fonctionne bien dans l’en- treprise. Les fonctionnalités et informations les plus importantes doivent être en premier plan et rapides d’accès. Conjointement au client, en observant les outils qui sont déjà utilisés, on définit la meilleure interface graphique pour un projet.
Enfin, l’interface graphique proposée à l’utilisateur peut être personnalisée en fonction de son poste, de son UO ou de sa place hiérarchique dans l’entreprise.
Ex : les collaborateurs auront une interface personnalisée permettant une gestion simple de leur propre identité, de leurs comptes et habilitations. Les managers auront une interface différente pour gérer a la fois ce qui les concerne et ce qui concerne les employés qu’ils managent. Enfin, les responsables d’UO auront une interface permettant de visualiser plus facilement les différentes identités qu’ils gèrent, les tâches à faire (certifications, approbations en attente, etc.) et les fonctionnalités qu’ils utilisent le plus.
L’interface peut aussi être personnalisée en fonction des options disponibles pour chaque collaborateur dans la solution.
Ex : tous les collaborateurs ont accès à des fonctionnalités les concernant comme la demande d’habilitation et la visibi- lité des informations liées à leur identité. Plus les privilèges dans l’entreprise sont importants, plus les fonctionnalités de la solution sont disponibles : on pense notamment à l’intelligence d’analyse permettant d’obtenir des rapports et des tableaux de bords sur les identités et les applications du SI qui n’est disponible que pour certains collaborateurs.
La finesse de personnalisation de l’interface graphique et de la page d’accueil demande de réfléchir la structure organisationnelle de l’entreprise et les besoins de chaque collaborateur. Plus l’interface sera facile d’accès, plus la solution s’intègrera dans la vie de l’entreprise et sera un atout.
Des exemples de pages d’accueil de solution d’IGA
Les formulaires
Les solutions d’IGA disposent de formulaires pour demander aux utilisateurs certaines informations néces- saires au fonctionnement de la solution.
Les formulaires peuvent être des supports pour des fonctionnalités telles que les demandes d’accès, les créa- tions d’identités, les modifications des informations d’une identité (déménagement, mutation, etc.). Dans ce cas, remplir le formulaire est la première étape du processus et le formulaire est disponible de façon permanente pour les utilisateurs.
Les formulaires peuvent également être des étapes des processus. Dans ce cas, le formulaire n’apparaît que quand l’information est nécessaire au processus, sous forme de pop-up, et ne sera plus disponible une fois validé.
Les champs d’un formulaire sont personnalisables : des listes cliquables, des champs formatés (NOM Prénom), des dates, des champs calculés et non modifiables (manager calculé en fonction de l’UO choisie), des valeurs par défaut modifiables, etc.
La validation d’un formulaire lance un processus adapté et prenant en compte les informations saisies.
L’un des enjeux est de les rendre très facile à utiliser en s’adaptant aux utilisateurs ciblés. Des tests des formu- laires en cours de développement peuvent être réalisés sur un panel de futurs utilisateurs pour prendre en compte dès la conception les éventuelles remarques des métiers. S’adapter au plus près des formulaires et processus déjà existants permet alors de limiter la conduite du changement.
L’automatisation des tâches
Les tâches permettent d’automatiser la mise à jour de la solution. Elles peuvent être lancées manuellement au besoin, programmées pour s’effectuer régulièrement ou programmées pour s’effectuer à des moments clefs (une tâche se terminant avec un résultat précis en déclenche une autre par exemple).
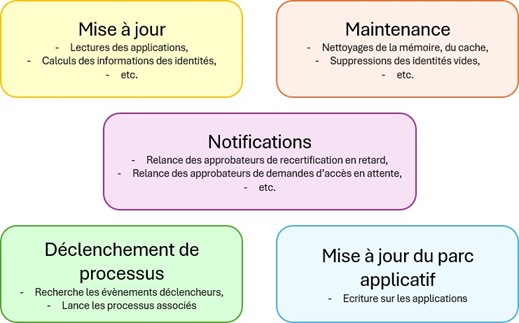
Exemple de différentes tâches
Des enchaînements de tâches peuvent être prévus pour la mise à jour de la solution ou d’autres besoins réguliers et trop conséquents pour être gérés par un simple processus.
Ex : La mise à jour de la solution peut demander de :
- Lire les données de l’application autoritaire
- Mettre à jour les cubes identités
- Déclencher les processus de création d’identité si de nouveaux comptes sont apparus sur l’application autoritaire
- Supprimer les identités qui n’ont plus de comptes sur l’application autoritaire,
- Lire les données des autres applications
- Lancer les processus relatifs aux politiques pour vérifier la conformité des habilitations et des comptes existants
- Mettre à jour les demandes d’accès (clôturer celles pour lesquelles les lectures ont montré que les accès sont bien attribués)
Les tâches disponibles et l’historique de leurs résultats permettent une maintenance de la solution sans inter- vention humaine et une traçabilité des informations importante : on sait grâce à l’historique quand est-ce que les informations sont obtenues et les processus sont déclenchés.
Mariann FAURE
Consultante Cybersécurité

