
Lorsque l’on souhaite envoyer dans un SIEM des logs en provenance de divers environnements, la solution communément déployée passe d’abord par une plateforme de centralisation qui servira de point d’entrée unique des données et de dispatcher vers le SIEM, un système d’archivage légal des logs, divers outils de monitoring, etc. La configuration de cette plateforme de centralisation peut vite se retrouver fastidieuse sur la durée : multiplicité des configurations, absence de suivi des évolutions modifications manuelles, retour arrière complexe en cas d’erreur, « tests en prod’ », etc. Ces problématiques sont d’autant plus exacerbées si la fonction de centralisation est portée par plusieurs serveurs. Nous verrons qu’en couplant des outils connus de CI/CD et avec les services « offerts » au sein d’AWS, nous pouvons adresser ces points relativement aisément.
Cet article est un retour d’expérience sur ce qui a pu être fait au sein d’un projet et n’a pas pour vocation de montrer un déploiement idéal, simplement d’aborder ce qu’il est possible de réaliser en s’appuyant sur un système existant.
Description de l’environnement
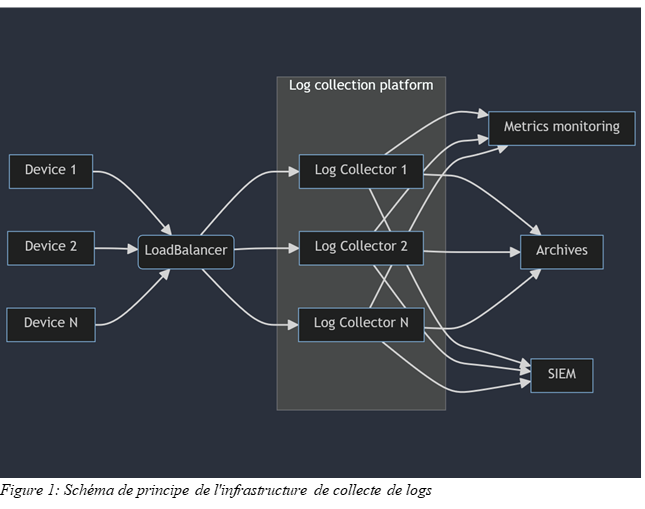
Architecture de la collecte
La centralisation des logs est hébergée au sein d’AWS sur des instances EC2. Ces instances EC2 sont publiées au monde extérieur à travers un LoadBalancer AWS. Le LoadBalancer écoute sur une série de port en UDP ou TCP. Tout flux arrivant sur ces ports sont redirigés vers les EC2 de collecte. Le LoadBalancer surveille lui-même la disponibilité des ports sur les instances EC2 afin de déterminer vers quelle(s) instance(s) le flux peut être dirigé.
Note : la configuration du LoadBalancer est en dehors du scope de cet article.
Le service présent sur les instances log collector est ici FluentD. Il s'agit d'un outil open-source permettant de collecter les logs via divers plugins inclus nativement dans l'application ou développés par la communauté.
Note : Nous parlons ici de FluentD mais les principes abordés dans cet article restent valables pour d’autres outils plus traditionnels comme Rsyslog ou syslog-ng.
Versioning, intégration et livraison en continu
Il est important, pour chaque modification (création/suppression/mise à jour) réalisée sur notre configuration de collecte, d’être capable de répondre à quelques questions :
-
De quelle modification s’agit-il ?
-
Qui a réalisé la modification ?
-
Quand a eu lieu cette modification ?
-
Pourquoi cette modification a-t-elle été réalisée ?
Stocker notre configuration dans un système de versioning nous permettra de stocker un historique de l’ensemble des modifications réalisées sur notre configuration ainsi que la réponse à ces quatre questions sous forme de métadonnées. On couplera à ce système de versioning un outil d’Intégration et de Déploiement Continu (Continuous Integration/Continuous Delivery, ou CI/CD) afin d’automatiser certaines actions quand des modifications seront effectuées sur notre configuration.
Il existe quelques outils portant ces fonctionnalités, notre choix s’arrêtera sur GitLab qui intègre tout ce dont nous avons besoin et que nous pouvons déployer au cœur de notre infrastructure.
Sécurisation de la plateforme
L’utilisation d’un outil de CI/CD peut induire l’apparition de nombreux risques de sécurité du fait de son objectif d’exécuter un ensemble de commandes au sein de l’infrastructure cible. On peut penser notamment à l’exécution de code arbitraire pouvant entraîner des indisponibilités de service au sein de la plateforme ou pouvant publier des informations confidentielles, volontairement (un acteur malveillant prenant la main sur le système de CI/CD) ou non (une erreur d’un opérateur). Il conviendra donc d’être particulièrement sensible à cette problématique et de régler le plus finement possible les permissions des différents systèmes engagés.
Pour la suite de l’article, les permissions nécessaires seront détaillées à chaque étape.
Branches et pipelines
L’utilisation de GitLab pour conserver notre configuration nous permet de définir des déclencheurs de notre CI/CD sur des évènements spécifiques. Notre besoin va être le suivant :
-
Tout changement de configuration poussé dans le dépôt Git ne doit pas systématiquement être déployé
-
Un ensemble de changements doit d’abord être validé sur un environnement d’intégration
-
Un déploiement en production ne peut être autorisé qu’une fois les changements validés en intégration
On appliquera donc la politique suivante :
-
La branche « main » du projet est l’image de la configuration en production et servira de base aux déploiements. On interdira tout changement en direct dans cette branche en la protégeant.
-
Une branche « integration » sera créée et servira de base pour les configurations à valider. De même que la branche « main », on interdira tout changement en direct dans cette branche en la protégeant
-
Une branche sera créée pour chaque ensemble de changements à appliquer à la plateforme de collecte (définition d’un nouveau périmètre de collecte, par exemple). Une fois les changements considérés comme terminés, la branche sera « mergée » dans la branche « integration »
-
Pour chaque « merge » dans la branche « integration », la configuration sera déployée sur un environnement d’intégration via le déclenchement d’un pipeline de la CI/CD. Si ce déploiement se déroule sans accrocs, le contenu de la branche « integration » sera « mergé » dans la branche « main »
-
Pour chaque « merge » dans la branche « main », un déploiement de la configuration sera effectué dans l’environnement de production via le déclenchement d’un pipeline de la CI/CD.
Le déploiement et la prise en compte de la configuration seront entièrement gérés par un pipeline de la CI/CD. Le déploiement en intégration ou en production sera réalisé exactement de la même manière et seules les cibles différeront. Pour ce faire, on utilisera la notion d’environnement au sein de GitLab qui permet de définir des valeurs différentes à une même variables. D’autres fonctionnalités sont également apportées comme l’assurance que seul le job de déploiement le plus récent pour un environnement donné s’exécute ou le suivi de chaque déploiement.
Déploiement de la configuration
Publication de la configuration
La publication de la configuration en tant que telle sera faite relativement simplement en poussant les fichiers de configuration dans un bucket S3. On pourra faire la distinction entre les plateformes de production et d’intégration en utilisant des buckets S3 différents ou en utilisant une arborescence différenciée au sein d’un bucket S3 unique. Pour être certain de ne pas conserver de configuration obsolète, on supprime d’abord le contenu déjà présent dans le bucket S3 avant d’y pousser la nouvelle version.
Pour permettre à notre CI/CD de publier les fichiers de configuration dans notre bucket S3, il sera nécessaire de donner à notre runner GitLab le droit de lister, de pousser et de supprimer des objets dans le stockage S3. Il faudra donc autoriser les actions suivantes :
-
s3:PutObject
-
s3:GetObject
-
s3:DeleteObject
Ces actions devront être autorisée idéalement sur les objets de configuration que nous allons pousser. Ici, il s’agira de
-
arn:aws:s3:::log-collection-bucket/configuration/integration/*
-
arn:aws:s3:::log-collection-bucket/configuration/production/*
Prise en compte de la configuration sur les instances de collecte
La première étape est passée : nous savons mettre à disposition la configuration à déployer sur nos serveurs de collecte. Reste maintenant à l’appliquer sur nos instances de collecte. Dans l’absolu, il s’agira de télécharger les fichiers stockés dans notre bucket S3, les comparer avec l’existant et, si une différence est identifiée, redémarrer le service. On pourra également déclencher une notification (en s’appuyant sur AWS SNS, par exemple) pour avertir les opérateurs du redémarrage réussi ou non du service de collecte.
La question est maintenant de déterminer comment lancer ces opérations. Nos instances étant hébergées dans AWS, nous pouvons nous appuyer sur la fonctionnalité « Run Command » du service AWS System Manager nous permettant d’exécuter une série de commandes depuis nos systèmes. Ces opérations seront lancées en parallèle et nous bénéficierons de l’audit réalisé à travers AWS CloudTrail si nécessaire.
Nous faisons évoluer la configuration de notre CI/CD en conséquence en y ajoutant l’appel à la commande AWS System Manager « SendCommand ». Dans notre exemple, l’exécution de la logique de redémarrage du service de collecte est réalisée par un script python situé directement sur nos systèmes à l’emplacement « /opt/log_collection/deploy.py » et prenant en seul paramètre l’adresse du bucket S3 contenant la configuration devant être appliquée.
D’un point de vue sécurité, l’appel de AWS System Manager peut s’avérer problématique car nous laissons la capacité d’exécuter des commandes à distance sur nos systèmes. Il faudra donc s’assurer que notre CI/CD n’a pas les permissions pour exécuter des commandes via System Manager que vers nos collecteurs de logs. En supposant que nous ayons tagué les instances composant notre plateforme de collecte en tant que « InstanceRole: LogCollection », la définition d’une ResourcePolicy comme suit permettant l’utilisation de l’action « ssm:SendCommand » nous garantira que seules la CI/CD ne pourra lancer des opérations à travers System Manager que vers les instances de collecte de logs.
Pour une sécurisation plus avancée, tout dépendra de la forme que prendra la script de déploiement : script interprété directement sur les systèmes cibles ou utilisation d’un SSM Document.
Et pour les secrets ?
On le sait, conserver des secrets directement dans un dépôt git est une très mauvaise pratique. Malheureusement, notre configuration peut nécessiter l’utilisation de secrets : certificat et clé privée pour la mise en place de possibilités de chiffrement d’une connexion TCP, identifiants pour l’accès à un service de stockage de fichiers, clé API pour l’accès à un service web, etc. Il est donc nécessaire de nous assurer qu’aucune de ces informations ne se retrouvent « en dur » dans notre configuration. Pour cela, nous utiliserons le service AWS Secret Manager nous permettant de stocker nos secrets afin de les mettre à disposition pour diverses utilisations.
Identifiants et clés API
La plupart des services de collectes peuvent accéder à des variables d’environnements. Nous allons donc nous appuyer sur cette fonctionnalité pour transmettre nos différents mots de passe, phrases de passe ou clés API à notre service de collecte.
Dans le cas de FluentD, le fichier d’environnement est disponible à l’emplacement « /etc/sysconfig/td-agent » et doit contenir les variables d’environnement qui seront chargées au démarrage du service sous la forme « export VAR1="foo" ». Notre script de déploiement de la configuration sera donc chargé de peupler ce fichier avec les secrets publiés dans AWS Secret Manager. Tout comme le reste de la configuration, on générera un fichier d’environnement temporaire qui sera comparé avec le fichier courant. Si des différences sont identifiées, le service de collecte devra alors être redémarré.
Pour la génération de ce fichier d’environnement, nous allons créer un fichier secrets.conf dans notre dépôt. Chaque ligne de ce fichier fera référence à un secret et sera formée comme suit : « env#var_name#aws_secret_arn ».
-
« env » est ici un mot clé qui nous servira plus tard à discriminer les entrées de ce fichier entre variables d’environnement et fichiers
-
« var_name » est le nom de la variable d’environnement tel qu’attendu par le service de collecte
-
« aws_secret_arn » est l’identifiant du secret stocké dans AWS Secret Manager
Certificats et clés privées
En fonction des méthodes de collecte choisies, il est possible que l’on soit amené à déployer des certificats et/ou des clés privées, que ce soit pour permettre la réception de flux chiffrés par TLS ou pour permettre l’authentification à des services distants par échange de clés. Nous pouvons stocker ces fichiers dans le dossier « /etc/td-agent/certs/ ».
La logique appliquée ici est équivalente à ce qu’on aura pu mettre en place pour les secrets stockés dans l’environnement et on va donc capitaliser sur le fichier « secrets.conf » précédemment créé et y ajouter des lignes sous la forme « file#file_name.pem#aws_secret_arn ». La différence vient du fait qu’au lieu de stocker les secrets sous la forme de variables d’environnement dans un fichier unique on copiera le contenu du secret AWS dans un fichier situé dans un dossier temporaire et nommé suivant les indications contenues dans le fichier secrets.conf. Une fois l’ensemble des secrets rapatriés sur le serveur local, si des différences sont présentes entre le dossier temporaire et le dossier utilisé par le service, on supprimera le contenu de ce dossier destination, copiera l’ensemble des données du dossier temporaire vers celui-ci et on permettra le redémarrage du service de collecte.
Sécurisation
Les fichiers identifiés plus haut sont particulièrement sensibles de part leur contenu. Il s’agira de bien en contrôler les accès afin de nous assurer que seul le service de collecte y ait accès. On ajoutera donc à notre script de déploiement les commandes adéquates nous assurer que le propriétaire du fichier « /etc/sysconfig/td-agent» et du dossier « etc/td-agent/secrets » et de son contenu est bien l’utilisateur avec lequel notre service de collecte est lancé et pour nous assurer que seul le propriétaire de ces fichier est en mesure de les lire.
Il sera de plus, nécessaire de donner les permissions aux instances EC2 hébergeant le service de collecte de lire et déchiffrer les secrets dans AWS Secret Manager. Il sera également nécessaire de bien restreindre ce droit aux seuls secrets nécessaires pour la collecte, en adoptant par exemple une convention de nommage pour nos secrets.
Mise en place de tests
Nous savons désormais déployer notre configuration et redémarrer la collecte des logs si nécessaire dans le cas où des changements doivent être pris en compte sur notre plateforme d’intégration ou sur notre plateforme de production.Si une configuration n’est pas valable, notre plateforme d’intégration ne sera pas capable de redémarrer, ce qui nous évitera de déployer sur la production et de rendre notre collecte indisponible. Le mieux serait toutefois de nous rendre compte que notre configuration n’est pas valide avant de déployer en intégration. Pour cela, nous allons mettre en place une logique nous permettant de tester et valider notre configuration à chaque modification publiée dans notre dépôt.
On va donc ajouter un stage dans la configuration de notre CI/CD que l’on appellera simplement « Test » ainsi qu’un job qui lui sera rattaché et qui sera exécuté systématiquement. Ce job se chargera dans un environnement ou FluentD sera pré-installé (l’utilisation d’une image docker est particulièrement utile ici) et il exécutera les mêmes commandes que le script de déploiement à une exception près. FluentD est capable de lancer une vérification de sa configuration et de s’arrêter. En présence d’une erreur de configuration, la commande échoue et remonte un code retour non nul. On remplacera donc dans le script de test la commande de redémarrage du service par la commande de validation de la configuration.
Désormais, si un échec a lieu lors de la génération de la configuration (impossibilité de récupérer un secret, par exemple) ou si la configuration est invalide (variable d’environnement non définie, erreur dans syntaxe du fichier de configuration), le job échouera, stoppant ainsi toute progression de notre CI/CD et bloquant donc les déploiements sur les environnements d’intégration ou de production. Il sera également possible de configurer le projet dans GitLab de façon à bloquer toute Merge Request tant que la CI/CD échoue, forçant de facto la présence d’une configuration syntaxiquement correcte dans les branche « integration » et « main » (et donc sur nos environnements d’intégration et de production).
Il est important de noter que le système sur lequel sera exécuté notre script de test devra avoir les mêmes permissions sur AWS Secrets Manager que nos instances EC2 d’intégration et de production. En effet, une partie des tests consiste à récupérer les secrets afin d’avoir une configuration correcte.
Sécurisation de la CI/CD
Nous savons désormais déployer notre configuration sur l’ensemble de nos systèmes tout en gérant nos différents secrets nécessaire à la bonne collecte de nos logs. Pour cela nous avons du donner un certain nombre de permissions sur notre environnement AWS aussi bien à nos systèmes cibles qu’à notre serveur exécutant notre CI/CD. En conséquence, le détournement de la CI/CD peut mener à la compromission du système de collecte de logs ou à la compromission des secrets y étant utilisés en modifiant les commandes exécutées lors des déploiements.
Généralement, la configuration de la CI/CD est incluse dans le dépôt du projet. Les utilisateurs ayant les droits en modification du contenu du projet pourront également modifier la configuration de la CI/CD. Ces changements seront bien évidemment suivis comme toute modification du projet mais pourraient être identifiés trop tard. Il devient donc nécessaire de verrouiller toute modification de la CI/CD pour notre projet.
Deux options deviennent donc envisageables :
-
en conservant la configuration de la CI/CD au sein du projet, nous pouvons configurer GitLab de façon à définit des proriétaires de code de façon à ce que chaque modification du fichier .gitlab-ci.yml (le fichier par défaut contenant la configuration de la CI/CD) soit validée et approuvée par une personne de confiance
-
en déplaçant le fichier .gitlab-ci.yml dans un projet externe et en modifiant la configuration de notre projet pour utiliser ce fichier externe. La configuration deviendra alors non accessible par les membres de notre projet de configuration de collecte des logs, aussi bien en lecture qu’en écriture. Cette solution nous permet ainsi de respecter le principe de moindre privilège, l’équipe en charge de la configuration de la collecte des logs n’ayant pas nécessairement besoin de connaître chaque étape suivie pour déployer cette configuration.
Conclusion
Il est tout à fait possible de concevoir un système permettant de déployer de façon sécurisée la configuration nécessaire pour collecter les données critiques pour un SIEM en parallèle sur de multiples « serveurs ». Les quelques mesures présentées restent toute fois une base de départ pour construire une système plus fiable et plus sûr. Parmi les mesures additionnelles envisageables, nous trouvons :
-
l’application dynamique des permissions sur les différents systèmes de façon à ce que nos instances ne puissent accéder aux secrets ou au bucket S3 contenant leur configuration de référence uniquement lors d’un déploiement
-
application d’une politique de non-répudiation des modifications déployées via le rejet des modifications non signées numériquement
-
la mise en place de revues de toute modification sur notre projet afin de limiter les risques de compromissions (volontaires ou non)
N’ayant pas encore pu expérimenter la mise en place de ce genre de mesures, celles-ci pourront être l’objet d’un futur article.

