

L'édition 2024 de l'All Days DevOps (ADDO) de Sonatype a rassemblé des experts du monde entier pour discuter des questions critiques en matière de sécurité logicielle, d'infrastructure et de développement cloud-native.
Au-delà des présentations individuelles, des thèmes transversaux sont apparus, révélant des tendances et des défis communs à tous les niveaux de l'ingénierie et de l'innovation logicielle. Ce RETEX regroupe ces sujets pour offrir une vue d'ensemble cohérente sur les enjeux et les solutions présentés lors de cet événement.
Sécurité des chaînes d'approvisionnement Open Source : une menace silencieuse

Les composants open source, omniprésents dans les chaînes d'approvisionnement logiciel modernes, sont devenus un vecteur d'attaque majeur pour les cybercriminels. Ilkka Turunen, Field CTO de Sonatype, a souligné la montée en puissance des malwares cachés au sein de ces composants. Ces attaques s'intègrent directement dans les systèmes d'information, souvent sans être détectées par les mesures de sécurité traditionnelles. Il est crucial de comprendre que les solutions réactives ne suffisent plus ; la prévention proactive est désormais une nécessité impérieuse.
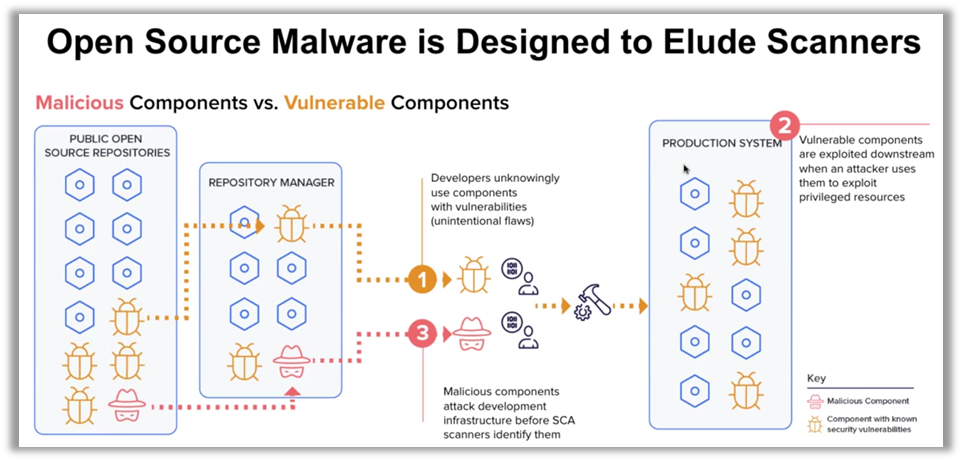
Les chiffres parlent d'eux-mêmes : environ 50 % des dépôts open source non protégés contiennent des paquets malveillants. Cela révèle une vulnérabilité fondamentale dans la manière dont les entreprises gèrent leurs chaînes d'approvisionnement. Pour surmonter cette menace, les organisations doivent repenser leur approche, en intégrant une vigilance continue et des stratégies de prévention bien en amont des cycles de développement.

"La sécurité de la chaîne d'approvisionnement logiciel ne consiste pas seulement à corriger des vulnérabilités, elle consiste à prévenir les attaques avant même qu'elles ne surviennent." 🚨 - Ilkka Turunen
Moderniser l'infrastructure avec la microinfrastructure
L'évolution vers une architecture de microservices a été une étape importante pour décentraliser et rendre plus agile le développement logiciel. Cependant, l'infrastructure sous-jacente n'a souvent pas suivi cette évolution. Pawel Piwosz de Tameshi propose le concept de microinfrastructure pour aligner l'infrastructure avec la modularité des microservices rendant chaque service plus autonome, flexible et résilient.
Cela implique une transformation profonde où chaque service bénéficie d'une infrastructure dédiée, conçue spécifiquement pour répondre à ses besoins uniques. En permettant une infrastructure modulaire, cette approche renforce non seulement la résilience mais aussi l'efficacité opérationnelle globale.

Ce modèle de microinfrastructure vise également à améliorer l'agilité de l'organisation en permettant aux équipes de développement de déployer et de modifier l'infrastructure rapidement et de manière indépendante. En fin de compte, la microinfrastructure est une réponse directe aux limitations des infrastructures monolithiques traditionnelles, offrant une meilleure réactivité face aux changements et une capacité accrue à évoluer en fonction des exigences du marché.

"L'infrastructure devrait être aussi flexible et légère que les services qu'elle soutient." 🛠️ - Pawel Piwosz
Plateformes de développement internes et opérateurs Kubernetes
Les plateformes de développement internes (IDP) sont devenues essentielles pour simplifier le travail des développeurs et améliorer leur productivité. George Hantzaras et Dan McKean de MongoDB ont mis en avant l'importance des opérateurs Kubernetes dans cette transformation. Ces opérateurs offrent une gestion plus efficace des applications complexes, en permettant des configurations standardisées et en réduisant la charge cognitive des équipes de développement.
Les opérateurs Kubernetes facilitent la création de plateformes robustes capables de supporter une multitude de services tout en maintenant la flexibilité nécessaire au bon fonctionnement des systèmes. Ils automatisent les tâches opérationnelles courantes, comme la mise à l'échelle des applications, la gestion des mises à jour et le contrôle de la santé des services, permettant ainsi aux développeurs de se concentrer sur l'écriture de code plutôt que sur des tâches administratives répétitives.

En combinant ces opérateurs à des solutions GitOps, les entreprises peuvent également tirer parti d'un modèle de gestion déclaratif, garantissant la cohérence et la reproductibilité des déploiements. ArgoCD, par exemple, permet de gérer l'état de l'infrastructure et des applications via des configurations stockées dans Git, assurant un contrôle de version clair et facilitant le retour à des états antérieurs en cas de problème. Cela réduit non seulement les erreurs humaines, mais améliore aussi la transparence et la collaboration entre les équipes.
Le recours aux opérateurs Kubernetes favorise également l'évolutivité de l'IDP, car chaque opérateur peut être spécifiquement conçu pour répondre aux besoins des différents services ou environnements. Cela permet une personnalisation fine et une gestion optimisée des ressources, garantissant que l'infrastructure reste agile et prête à s'adapter aux évolutions rapides des exigences commerciales.
"Les opérateurs Kubernetes sont la clé pour transformer Kubernetes en une véritable plateforme de plateformes." 🔧 - George Hantzaras
Platform engineering : les leçons apprises
Geert van der Cruijsen de Xebia a partagé son expérience sur les erreurs courantes qui se produisent souvent dans la mise en place des plateformes de développement. Le platform engineering peut être une source puissante d'efficacité, mais seulement si les pièges habituels sont évités. Parmi les erreurs les plus fréquentes, on trouve le manque de prise en compte des besoins des développeurs, la composition d'équipes mal adaptées, et la mise en œuvre d'une plateforme imposée aux utilisateurs plutôt que conçue pour eux.

L'une des erreurs majeures est de traiter la plateforme comme une infrastructure technique sans considérer l'expérience utilisateur des développeurs. Une plateforme efficace doit être pensée comme un produit, avec des développeurs en tant que clients. Cela signifie recueillir constamment des retours, affiner les fonctionnalités et garantir que la plateforme s'aligne sur les besoins en évolution des équipes. Geert van der Cruijsen insiste sur l'importance de ne pas tomber dans le piège du "build it and they will come" : une plateforme, même techniquement performante, ne sera adoptée que si elle apporte une réelle valeur ajoutée au quotidien des utilisateurs.
De plus, la composition des équipes responsables du développement et de la maintenance des plateformes est cruciale. Renommer équipe existante de DevOps ou de Cloud Engineering en "Platform Team" sans ajuster sa mission et ses compétences ne fonctionne pas. Une équipe de plateforme doit être structurée pour se concentrer sur la création de produits destinés aux équipes de développement, en facilitant leur travail sans s'impliquer directement dans les opérations quotidiennes.

L'imposition d'une plateforme, plutôt que son adoption naturelle, est également une erreur courante. Les développeurs doivent être encouragés à utiliser la plateforme, non pas contraints. Cela passe par la création d'une valeur perçue élevée, l'élimination des frictions, et la mise en place de solutions qui répondent aux vrais problèmes rencontrés par les développeurs. Sinon, des initiatives parallèles et des systèmes "Shadow IT" émergeront, rendant la plateforme officielle inefficace.

Enfin, il est essentiel de mesurer le ROI et d'analyser les points de blocage. Le succès d'une plateforme ne se mesure pas seulement par sa mise en œuvre, mais par l'impact qu'elle a sur la productivité des développeurs, la rapidité des livraisons et la qualité des logiciels produits.
Cela implique d'utiliser des métriques telles que le temps de cycle, le taux d'adoption et la satisfaction des développeurs, afin de comprendre ce qui fonctionne bien et ce qui nécessite des ajustements.
"Une plateforme qui ne répond pas aux besoins réels de ses utilisateurs devient un obstacle plutôt qu'un accélérateur." 🚧 - Geert van der Cruijsen
Vers des plateformes antifragiles
Manuel Pais, auteur de Team Topologies, a abordé l'idée d'une plateforme antifragile — une plateforme qui ne se contente pas de survivre aux crises, mais qui s'améliore à travers elles. Pour rendre une plateforme antifragile, il est nécessaire de la concevoir de manière qu'elle puisse s'adapter et se renforcer face aux aléas économiques et organisationnels. Cela implique de démontrer constamment sa valeur aux utilisateurs, non seulement en interne mais aussi à travers l'ensemble de l'organisation.
Les piliers d'une telle plateforme incluent la confiance interne et externe, ainsi que le partage de réussites. Manuel Pais insiste sur l'importance de mesurer non seulement l'adoption de la plateforme, mais aussi la satisfaction des utilisateurs et la fiabilité des services fournis.
La création d'une plateforme antifragile commence par l'établissement d'une culture de collaboration et de communication transparente. Les équipes doivent être encouragées à signaler les problèmes, à expérimenter des solutions, et à apprendre des erreurs, de manière à transformer les échecs potentiels en opportunités d'amélioration. En cultivant cette capacité à tirer parti des perturbations, les plateformes deviennent non seulement résilientes, mais également capables de se renforcer face aux défis.
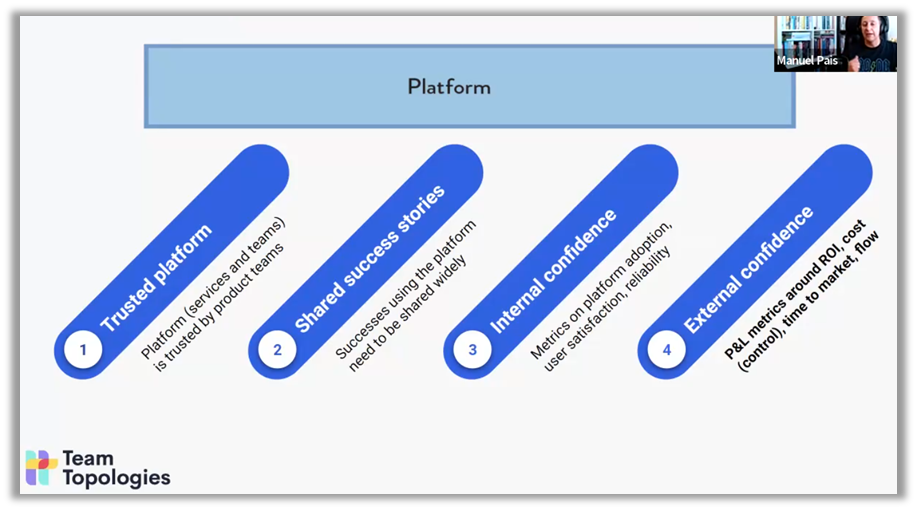
Un autre aspect essentiel est la capacité à itérer rapidement et à évoluer. Cela nécessite l'utilisation de métriques claires pour évaluer la performance, telles que la fiabilité, l'adoption et la satisfaction des utilisateurs. Ces indicateurs permettent de prendre des décisions éclairées pour ajuster les fonctionnalités et répondre aux besoins changeants des équipes de développement. Manuel Pais recommande également de partager largement les histoires de succès — des exemples concrets où la plateforme a aidé une équipe à résoudre un problème ou à gagner en efficacité — afin de renforcer la confiance dans la valeur de la plateforme.

En termes de gouvernance, une plateforme antifragile doit être soutenue par des processus qui favorisent la flexibilité plutôt que la rigidité. Plutôt que d'imposer des règles strictes, il s'agit de fournir des lignes directrices qui permettent aux équipes d'innover tout en restant alignées sur les objectifs globaux de l'organisation. Cela crée un environnement où les équipes ont la liberté d'expérimenter tout en minimisant les risques, renforçant ainsi la robustesse de la plateforme.
"Une plateforme antifragile s'améliore et prospère face aux défis." 💪 - Manuel Pais
L'évolution des chaînes d'approvisionnement logiciel : opportunités et défis
L’adoption massive de l'open source a radicalement transformé les chaînes d'approvisionnement logiciel au cours de la dernière décennie. Les avantages sont nombreux : une accélération du développement, une réduction des coûts, et l'accès à une communauté mondiale d'innovateurs. Cependant, cette transformation a également accru la surface d'attaque, exposant les entreprises à de nouveaux risques liés à la sécurité de leurs dépendances open source. Brian Fox, CTO de Sonatype, a mis en lumière ces défis lors de sa présentation, soulignant à quel point la complexité croissante des chaînes d'approvisionnement représente un défi considérable pour les équipes de développement et de sécurité.
Fox a également partagé les résultats du 10e rapport annuel sur l'état de la chaîne d'approvisionnement logicielle de Sonatype. Ce rapport met en évidence une augmentation de 1 466 % de la fréquence de publication des packages open source au cours de la dernière décennie, illustrant la rapidité avec laquelle l'open source évolue. En parallèle, le MTTR (temps moyen de réparation) a connu une augmentation de 800 %, passant de 50 jours à 400 jours en seulement sept ans, tandis que le nombre de CVE (Common Vulnerabilities and Exposures) a grimpé de 2 000 à près de 30 000 en 25 ans, soit une augmentation de près de 1 500%.


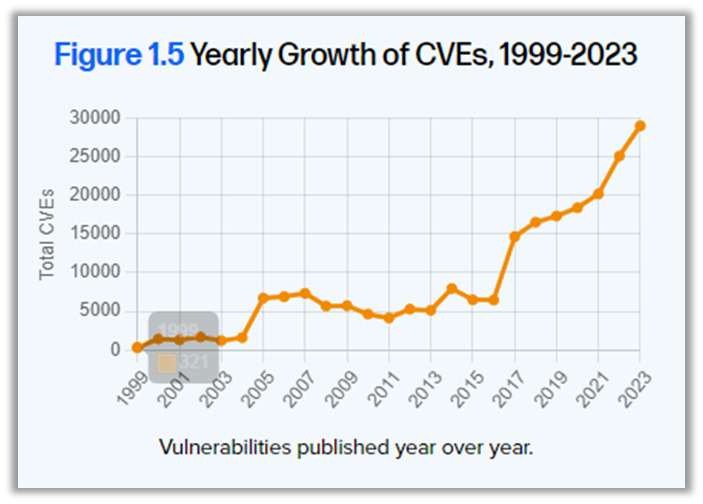
Ces chiffres montrent clairement l'ampleur des défis auxquels les entreprises doivent faire face en matière de sécurité des chaînes d'approvisionnement. En fait, 96 % des projets open source vulnérables n'ont pas été mis à jour, créant ainsi une opportunité évidente pour les cyberattaquants d'exploiter ces faiblesses.

Pour répondre à ces défis, Brian Fox a souligné l'importance de repenser la gouvernance des chaînes d'approvisionnement. Il ne s'agit pas seulement de réagir aux vulnérabilités après coup, mais d'intégrer des pratiques de sécurité dès le début du cycle de développement, un concept bien connu sous le nom de "shift left".
Il est nécessaire de promouvoir une culture de la sécurité au sein des équipes de développement. Cela signifie qu'il est essentiel de responsabiliser les développeurs et de les encourager à considérer la sécurité comme faisant partie intégrante de leur travail quotidien. Cela passe par une collaboration étroite entre les équipes de développement et de sécurité, des processus rigoureux de gouvernance, et l'adoption d'outils qui facilitent la détection et la correction des vulnérabilités sans perturber le flux de travail.
Les entreprises doivent participer activement à l'amélioration de la sécurité des composants qu'elles utilisent, plutôt que de se contenter de consommer des logiciels open source. En contribuant à des projets open source, en signalant des vulnérabilités et en partageant des correctifs, les organisations renforcent non seulement leur propre sécurité, mais également celle de l'ensemble de l'écosystème. Cette démarche collaborative est essentielle pour réduire la surface d'attaque et renforcer la résilience des chaînes d'approvisionnement.
Il est également crucial de mettre en place des processus de validation continue dans les pipelines d'intégration et de déploiement (CI/CD). Ces processus doivent inclure des audits réguliers des composants tiers et une vérification automatisée des dépendances à chaque étape du cycle de développement. Cela permet de garantir que les nouvelles versions des logiciels intègrent des composants sécurisés et à jour, réduisant ainsi la probabilité d'introduire des vulnérabilités exploitables.
Les outils de scanners de composition logicielle (SCA) peuvent non seulement identifier les vulnérabilités mais aussi recommander des versions plus sûres, facilitant ainsi la gestion des dépendances de manière proactive.
En conclusion, l'évolution des chaînes d'approvisionnement logiciel open source apporte des opportunités significatives, telles que la rapidité et l'innovation collaborative, mais elle comporte également des défis majeurs en termes de sécurité. Pour en tirer le meilleur parti tout en minimisant les risques, il est essentiel d'adopter une approche proactive de la sécurité, de renforcer la gouvernance des dépendances et de promouvoir une culture de la sécurité partagée au sein des équipes. En combinant des outils de pointe, une collaboration active et une vigilance continue, les entreprises peuvent garantir la résilience et la fiabilité de leurs logiciels dans un paysage de menaces de plus en plus complexe.
"La complexité croissante des chaînes d'approvisionnement nécessite des stratégies proactives pour garantir la sécurité et la résilience." 🔒 - Brian Fox
Applications cloud-native et résilience
Avec les architectures cloud-native, la scalabilité et la flexibilité deviennent des caractéristiques inhérentes, mais la résilience reste un défi majeur. Ricardo Castro de Blip/FanDuel a présenté diverses stratégies permettant de concevoir des applications capables de résister aux pannes. Ces stratégies incluent des déploiements Blue/Green, des déploiements canary, ainsi que l'utilisation de Dark Launches pour minimiser les risques lors des mises en production.
Les déploiements Blue/Green permettent de maintenir deux environnements parallèles, garantissant une transition fluide lors des mises à jour. Cela réduit les interruptions de service et facilite les retours en arrière en cas de problème. Les déploiements canary offrent quant à eux une approche progressive, en déployant les nouvelles versions à un sous-ensemble d'utilisateurs afin d'identifier les éventuels problèmes avant une mise en production généralisée. Les Dark Launches permettent de tester de nouvelles fonctionnalités en production sans les exposer directement aux utilisateurs, ce qui donne la possibilité de recueillir des données réelles tout en limitant les risques.

Les patterns de résilience en runtime, tels que les Circuit Breakers et les Bulkheads, sont également cruciaux pour garantir la robustesse des applications. Les Circuit Breakers agissent comme des disjoncteurs en désactivant temporairement les services défaillants, empêchant ainsi la propagation des erreurs dans l'ensemble du système. Les Bulkheads, inspirés des compartiments des navires, isolent différentes parties du système afin de limiter l'impact des défaillances sur d'autres composants. Ces pratiques sont essentielles pour empêcher un échec isolé de se transformer en une panne complète du système.
"Construire des applications cloud-native résilientes nécessite une combinaison de stratégies de déploiement intelligentes et de mécanismes de protection adaptés." ☁️⚡ - Ricardo Castro

Une autre stratégie clé est l'utilisation de timeouts et retries, qui permettent de gérer les échecs intermittents en limitant le temps d'attente pour une réponse et en réessayant les opérations échouées. Cela aide à éviter les blocages prolongés qui peuvent nuire à la performance globale. De plus, le rate limiting est une technique importante pour contrôler le nombre de requêtes adressées à un service, empêchant ainsi une surcharge qui pourrait dégrader la qualité de service.

Ricardo Castro a également insisté sur l'importance de l'observabilité dans les architectures cloud-native. Pour construire des systèmes résilients, il est indispensable de disposer d'une visibilité complète sur l'état des services, grâce à des outils de monitoring, de logging et de traçage distribué. Ces outils permettent non seulement de détecter rapidement les problèmes, mais aussi d'identifier leur origine et de mettre en place des actions correctives efficaces.
La résilience des applications cloud-native repose donc sur une combinaison de stratégies de déploiement intelligentes, de mécanismes de protection runtime, et d'une observabilité accrue. Ces éléments, lorsqu'ils sont bien intégrés, permettent de garantir une continuité de service et une expérience utilisateur de qualité, même face à des défaillances imprévues.
Construire un futur résilient
La résilience des plateformes et la sécurité de l'open source sont des enjeux stratégiques incontournables pour les entreprises modernes. Dans un environnement où les menaces sont de plus en plus sophistiquées, une approche proactive est essentielle. Cela passe par une surveillance continue, l'innovation en matière de sécurité, et une collaboration étroite avec la communauté open source, qui sont autant de leviers pour relever les défis actuels et à venir. Comme l'a exprimé Brian Fox, la sécurité proactive doit être vue comme un investissement stratégique et non comme un simple coût, car elle permet de construire des systèmes capables de non seulement résister aux crises, mais aussi de prospérer grâce à elles.
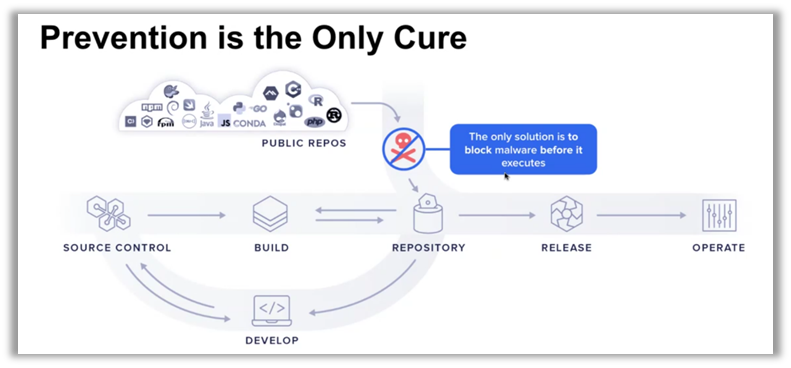
La résilience ne se limite pas à la protection contre les menaces : elle implique également une capacité d'apprentissage et d'amélioration continue face aux incidents. Cette philosophie repose sur l'intégration des meilleures pratiques de sécurité tout au long du cycle de développement, ainsi que sur la mise en place de processus qui permettent une réaction rapide et ciblée face aux attaques. L'utilisation d'outils d'observabilité, de monitoring et d'analyses en temps réel est primordiale pour garantir une visibilité complète sur l'état des systèmes, identifier rapidement les défaillances, et apporter des corrections avant qu'elles ne deviennent critiques.
En assurant une visibilité complète sur les opérations et les composants, les organisations peuvent identifier non seulement les incidents visibles, mais aussi les faiblesses sous-jacentes qui pourraient les rendre vulnérables à des attaques futures. Les entreprises doivent également s'appuyer sur l'automatisation assisté par IA afin de permettre une réponse rapide, allouer efficacement les ressources nécessaires à la résolution des incidents et minimiser l'impact sur les opérations ayant peu de valeur ajoutée pour l’action manuelle humaine.

De plus, la collaboration avec la communauté open source joue un rôle essentiel dans la construction de cette résilience. En partageant les informations sur les nouvelles menaces et en participant activement à l'amélioration des outils open source, les entreprises contribuent à la sécurité collective de l'écosystème. Cette collaboration favorise un cercle vertueux : chaque contribution individuelle renforce non seulement la sécurité de l'organisation contributrice, mais aussi celle de l'ensemble de la communauté. Cela permet de mutualiser les connaissances et les solutions, ce qui est particulièrement crucial face aux menaces globales.
"La sécurité proactive n'est pas un coût, c'est un investissement pour construire des systèmes antifragiles qui prospèrent face à l'adversité." 🔐💡 - Brian Fox
Il est temps pour les leaders technologiques de se demander si leurs stratégies actuelles sont à la hauteur de cette exigence de résilience, ou s'il reste encore des marges d'amélioration. 💭
Pour ceux et celles qui souhaitent approfondir les sujets abordés lors de l'All Days DevOps 2024, les sessions enregistrées sont disponibles à la demande permettant de revisiter les interventions des experts et de mieux comprendre les enjeux et les solutions discutés. Vous pouvez accéder aux vidéos via le site officiel : All Day DevOps.
Lionel GAIROARD
Practice Leader DevSecOps

